Publications
* Equal contribution; † Corresponding Authors; cs: coming soon.
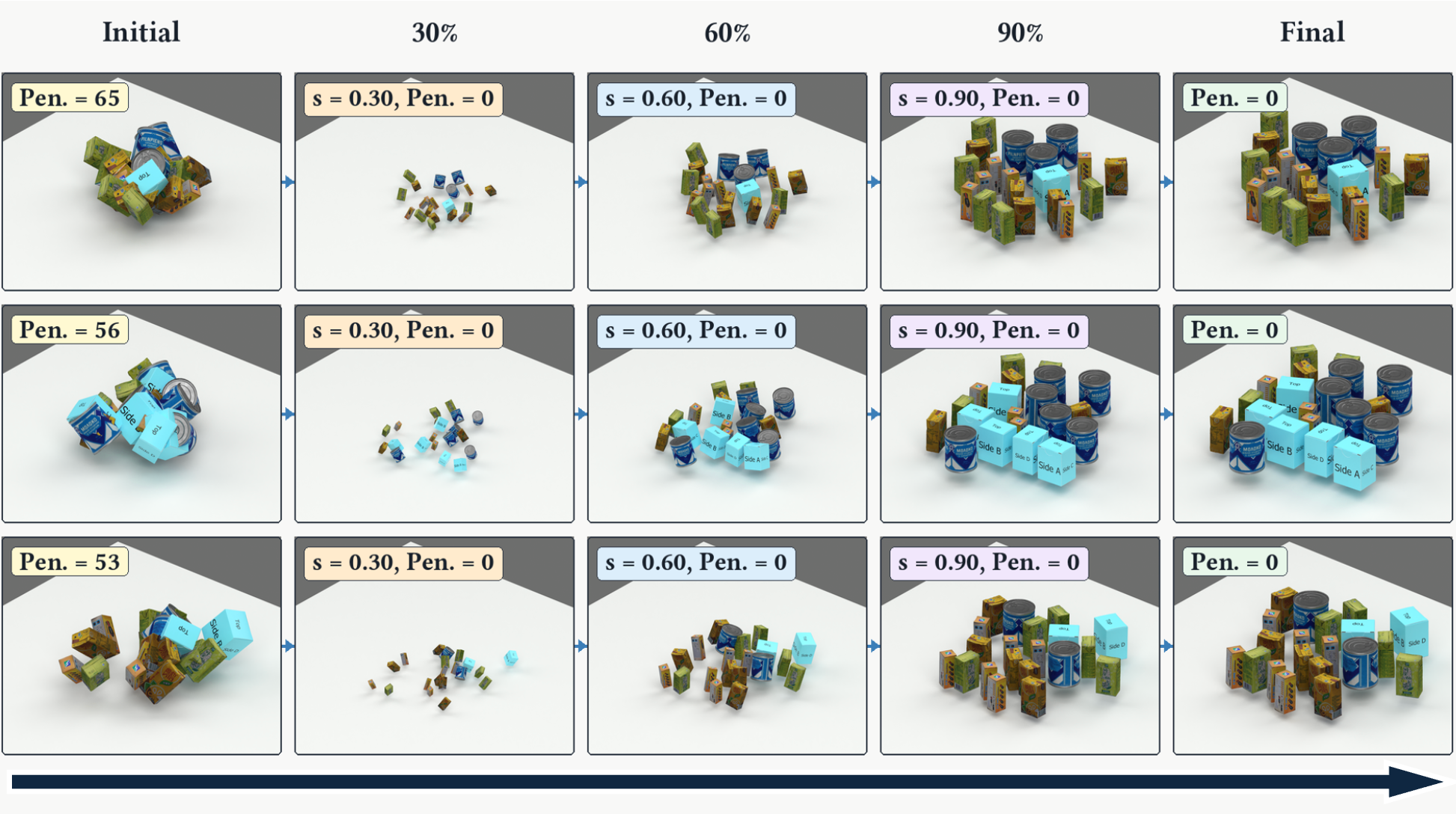
S4R: Progressive Scaling for Rigid Body Interpenetration Resolving
Zhiyang Dou*, Ang Zhao*, Chen Peng, Minghao Guo, Haixu Wu, Cheng Lin, Yuan Liu, Junfeng Yao, Xiaohu Guo, Wenping Wang, Wojciech Matusik.
ACM Transactions on Graphics (SIGGRAPH Asia 2026), Conditionally Accepted.
Zhiyang Dou*, Ang Zhao*, Chen Peng, Minghao Guo, Haixu Wu, Cheng Lin, Yuan Liu, Junfeng Yao, Xiaohu Guo, Wenping Wang, Wojciech Matusik.
ACM Transactions on Graphics (SIGGRAPH Asia 2026), Conditionally Accepted.
- project page (cs)
- paper (cs)
-
abstract
Resolving rigid-body interpenetration is a common preprocessing step in physical simulation, procedural generation, and robotic scene synthesis. Existing methods either rely on local projection heuristics that can cycle on dense non-convex contacts, or solve global optimization problems whose linearizations become unreliable under deep penetration. We introduce S4R, a continuation method that resolves interpenetration by following a uniform scale parameter. The method starts from a collision-free, down-scaled state and progressively restores all bodies to full size, solving at each scale step a sparse convex quadratic program that applies the minimum-norm displacement needed to maintain clearance. Uniform scaling makes surface-point trajectories linear in the scale parameter, allowing contact events and signed-distance updates to be predicted analytically between full mesh queries. This avoids linearizing deeply interpenetrating configurations and keeps each subproblem near shallow contact. A final refinement stage verifies the full-scale configuration and corrects any remaining violations. We evaluate S4R on Kubric, HY3D-Bench, and Thingi10K with up to 5000 bodies. In the main benchmark settings, S4R resolves configurations to zero mesh-level penetration within the time budget, while maintaining low centroid displacement and consistently outperforming optimization-based baselines in wall time. Upon publication, we will release the S4R source code and the datasets, generated scenes, and splits used by our experiments.
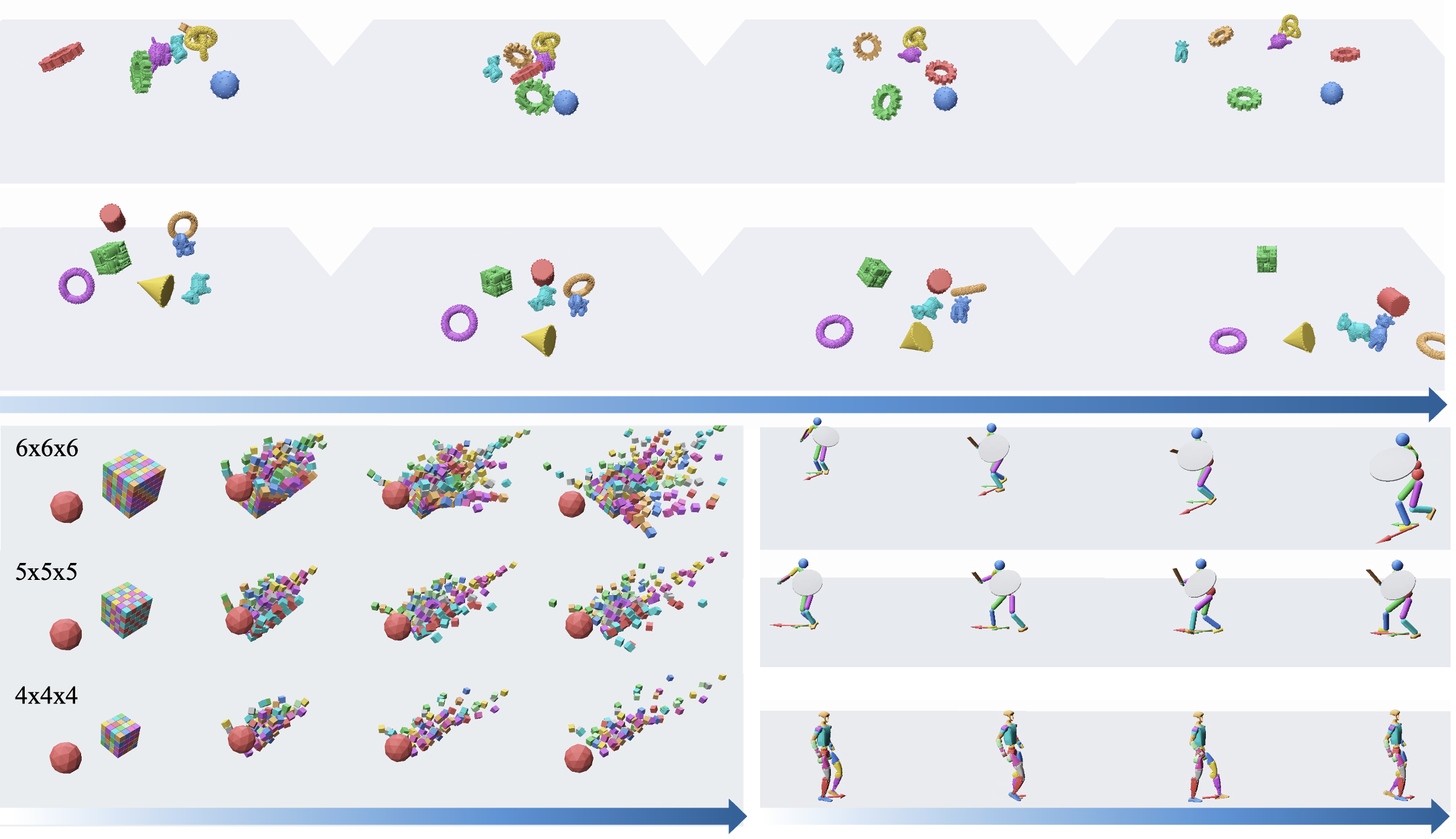
RigidFormer: Learning Rigid Dynamics and Beyond with Transformers
Zhiyang Dou, Minghao Guo, Haixu Wu, Doug Roble, Tuur Stuyck, Wojciech Matusik.
arXiv 2026.
Workshop Presentation: RSS 2026 Geometry of Motion, DAROMA, Sim2Real, and R-WM.
Zhiyang Dou, Minghao Guo, Haixu Wu, Doug Roble, Tuur Stuyck, Wojciech Matusik.
arXiv 2026.
Workshop Presentation: RSS 2026 Geometry of Motion, DAROMA, Sim2Real, and R-WM.
- project page
- paper
- code
-
abstract
Learning-based simulation of multi-object rigid-body dynamics remains difficult because contact is discontinuous and errors compound over long horizons. Most existing methods remain tied to mesh connectivity and vertex-level message passing, which limits their applicability to mesh-free inputs such as point clouds and leads to high computational cost. Efficiently modeling high-fidelity rigid-body dynamics from mesh-free representations therefore remains challenging. We introduce RigidFormer, an object-centric Transformer-based model that learns mesh-free rigid-body dynamics with controllable integration step sizes. RigidFormer reasons at the object level and advances each object through compact anchors; Anchor-Vertex Pooling enriches these anchors with local vertex features, retaining contact-relevant geometry without dense vertex-level interaction. We propose Anchor-based RoPE to inject anchor geometry into attention while respecting the unordered nature of objects and anchors: object-token processing is permutation-equivariant, and the mean-pooled anchor descriptor is invariant to anchor reindexing while preserving shape extent. RigidFormer further enforces rigidity by projecting updates onto the rigid-body manifold using differentiable Kabsch alignment. On standard benchmarks, RigidFormer outperforms or matches mesh-based baselines using point inputs, runs faster, generalizes to unseen point resolutions and across datasets, and scales to 200+ objects; we also show a preliminary extension to command-conditioned articulated bodies by treating body parts as interacting object-level components.
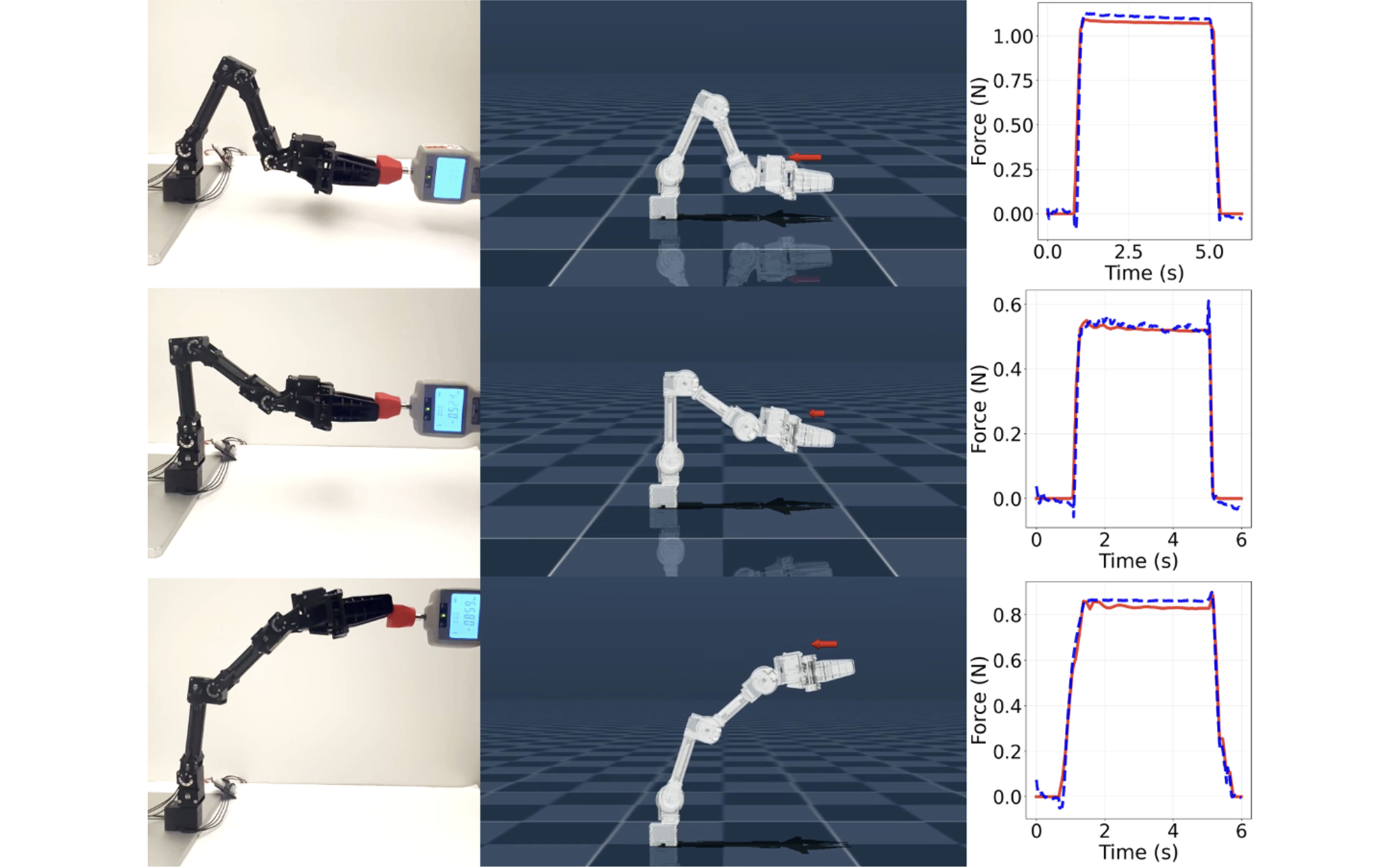
NeuralActuator: Neural Actuation Modeling for Robot Dynamics and External Force Perception
Zhiyang Dou, John U. Onyemelukwe, Hangxing Zhang, Heng Zhang, Minghao Guo, Yunsheng Tian, Michal Piotr Lipiec, Joshua Jacob, Chao Liu, Peter Yichen Chen, Yuri Ivanov, Wojciech Matusik.
Robotics: Science and Systems (RSS) 2026.
Outstanding Systems Paper Award at RSS 2026.
Workshop Presentation: RSS 2026 WPCIS, Sim2Real, and Tactile for FM.
Zhiyang Dou, John U. Onyemelukwe, Hangxing Zhang, Heng Zhang, Minghao Guo, Yunsheng Tian, Michal Piotr Lipiec, Joshua Jacob, Chao Liu, Peter Yichen Chen, Yuri Ivanov, Wojciech Matusik.
Robotics: Science and Systems (RSS) 2026.
Outstanding Systems Paper Award at RSS 2026.
Workshop Presentation: RSS 2026 WPCIS, Sim2Real, and Tactile for FM.
- project page
- paper
- poster
- code
-
abstract
Differentiable simulators have advanced policy learning and model-based control across robotic tasks. Yet actuator dynamics remain underexplored and can be a major source of sim-to-real error, particularly on low-cost platforms, where the linear current-to-joint-torque approximation becomes unreliable because of friction, hysteresis, backlash, and thermal effects. Accurate actuator models can also support force perception and integrated force/position control. We present NeuralActuator, which jointly predicts (i) a torque surrogate for trajectory propagation on low-cost servo platforms, (ii) external forces with a contact-probability gate for sensorless force perception, and (iii) a motor-condition score for a supervised joint, distinguishing normal from mechanically restricted operation. A twin-arm teleoperation system records robot states and actuator telemetry alongside external-force labels, yielding the Neural Actuation Dataset (NAD). The torque-surrogate head is trained through differentiable simulation from pose trajectories without ground-truth joint-torque measurements. A Transformer captures temporal dependencies while enabling real-time inference. We validate NeuralActuator on a 5-DoF OpenManipulator-X, a 6-DoF SO-101 from LeRobot, and a 7-DoF Franka Emika Panda, spanning three actuator families and costs from approximately $500 to more than $30,000. The low-cost platforms support physically plausible dynamics and force evaluation, while the offline Franka experiment provides a payload-force-estimation benchmark. We also demonstrate motor-condition estimation and improved behavior-cloning performance using NeuralActuator as a pretrained module. We release the dataset, code, and hardware configurations on the project page.

Hear-to-Act: Spatial Audio-Guided Robot Control on Humanoid and Manipulator Platforms
Zhiyang Dou, Yuxin Ray Song, Yuxiang Ma, Weirui Ye, Pengfei Ye, Shuyang Xu, Jason Xinyu Liu, Kaichen Zhou, Chuang Gan, Taku Komura, Paul Pu Liang, Wojciech Matusik.
Workshop Presentation: RSS 2026 FPA and RoboData.
Zhiyang Dou, Yuxin Ray Song, Yuxiang Ma, Weirui Ye, Pengfei Ye, Shuyang Xu, Jason Xinyu Liu, Kaichen Zhou, Chuang Gan, Taku Komura, Paul Pu Liang, Wojciech Matusik.
Workshop Presentation: RSS 2026 FPA and RoboData.
- paper
-
abstract
The direction of a sound is a perceptual cue that robots seldom exploit, although it reaches them through occlusions and outside the field of view. Recent work that drives motion generation from binaural audio showed that this signal is a rich perceptual representation: it carries enough spatial information to drive realistic, responsive human motion. Turning that representation into action on real robots requires three pieces a motion generator does not provide: robot-mounted spatial hearing, a way to collect spatial audio-conditioned robot demonstrations, and controllers that act on the perceived sound. We take a first step toward all three. We equip two platforms (a Unitree G1 humanoid and an OpenManipulator-X arm) with a binaural microphone pair at left/right "ear" positions, reproducing the inter-aural cues that human listeners rely on. To collect responsive demonstrations, we build a teleoperation rig that streams the robot's binaural hearing to the operator's two ears in real time, so the operator perceives the scene spatially as the robot does and teleoperates the matching reaction. Finally, we train a Transformer policy on the collected data that orients a robot toward an active sound source. Together these close the loop from binaural perception to robot action on both humanoid and manipulator platforms.

Robot Skill Puzzles: Decentralized Skill Priors for Humanoid–Environment Interaction
Zhiyang Dou*§, Jintao Lu*, Boyang Yu*, Zeyu Cao, Cheng Lin, Yuan Liu, Taku Komura.
Workshop Presentation: RSS 2026 SemRob, WCBM, and FM4RoboPlan.
§ Work done while at HKU.
Zhiyang Dou*§, Jintao Lu*, Boyang Yu*, Zeyu Cao, Cheng Lin, Yuan Liu, Taku Komura.
Workshop Presentation: RSS 2026 SemRob, WCBM, and FM4RoboPlan.
§ Work done while at HKU.
- paper (cs)
-
abstract
Behavior foundation models are becoming a practical substrate for generalist robot control, yet they still face a misaligned scaling target: a single resident policy is expected to internalize the geometry, articulation, force limits, affordance frames, and safe modes of use for a growing long tail of objects. We propose Robot Skill Puzzles (RSPs), a decentralized alternative in which an object exposes a signed, typed action artifact containing articulated assets, reference kinematics, advisory constraints, and optionally a compact object-specific controller. The robot verifies this artifact, maps its task-space interface to its own morphology, and executes it only through a robot-owned safety envelope. This keeps actuator authority on the robot while moving object-local interaction priors to the source best positioned to specify and maintain them. We formalize RSPs as object-resident contracts, state validity and safety conditions, and give a capacity argument separating resident controller footprint from object-catalog size. In a synthetic scaling study over 1000 action skills, a fixed-capacity centralized controller reaches 0.54 normalized error at matched resident footprint, whereas a decentralized backbone-plus-action-head scheme remains near 0.14. In a physics-based InterMimic study, warm-starting object controllers from a shared prior improves whole-body tracking on five held-out objects under the same short fine-tuning budget. We adapt the framework to behavior foundation models by treating RSPs as verified object-local priors for planning, semantic grounding, whole-body execution, and long-horizon recovery.

DSAD: Dynamic Soft Anisotropic Diagrams for Reduced-Order Video Representation
Zhiyang Dou, Laki Iinbor, Wojciech Matusik.
2026.
Zhiyang Dou, Laki Iinbor, Wojciech Matusik.
2026.
- project page (cs)
- paper (cs)
- code (cs)
-
abstract
Efficient video representations should do more than predict pixels: for a long video to be trainable, decodable, and budgeted, appearance and motion must be assigned to explicit units. Group-of-Pictures (GoP) primitive representations provide such units by fitting short blocks with canonical local elements, but their deformation is often still predicted by a neural head. Conversely, implicit neural representations achieve compact global fits without exposing local units that can be moved, ranked, or pruned. We observe that a short GoP contains many primitives but only a few independent motion patterns, suggesting that the same local ownership system used for appearance should also define the motion basis. We introduce Dynamic Soft Anisotropic Diagrams (DSAD), an explicit representation built from three layers over a shared soft-distance geometry. First, a Soft Anisotropic Diagram, defined as a top-K-masked softmax over anisotropic-Apollonius sites, provides a canonical coordinate family in which dense sites encode local RGB ownership. Second, a coarser anchor set reuses the SAD geometry so that anchor weights form a partition-of-unity motion basis without an additional neural module. Third, a reduced-order model (ROM) factorizes deformation into this spatial motion basis and knot-based temporal coefficients. This construction unifies appearance and motion within a single diagram while decoupling spatial ownership from temporal dynamics. On Bunny, UVG, and DAVIS, DSAD attains the highest PSNR among primitive representations and the highest DAVIS PSNR among the compared methods, while using a leaner per-GoP deformation module and providing a controllable rank-M anchor budget. Ablations and RAFT spectra link these gains to low-rank GoP motion and sharper appearance ownership. Code and trained models will be released.

Soft Anisotropic Diagrams for Differentiable Image Representation
Laki Iinbor, Zhiyang Dou†, Wojciech Matusik†.
† Joint Last Author.
ACM Transactions on Graphics (SIGGRAPH 2026).
Laki Iinbor, Zhiyang Dou†, Wojciech Matusik†.
† Joint Last Author.
ACM Transactions on Graphics (SIGGRAPH 2026).
- project page
- paper
- code
-
abstract
We introduce Soft Anisotropic Diagrams (SAD), an explicit and differentiable image representation parameterized by a set of adaptive sites in the image plane. In SAD, each site specifies an anisotropic metric and an additively weighted distance score, and we compute pixel colors as a softmax blend over a small per-pixel top-K subset of sites. We induce a soft anisotropic additively weighted Voronoi partition (i.e., an Apollonius diagram) with learnable per-site temperatures, preserving informative gradients while allowing clear, content-aligned boundaries and explicit ownership. Such a formulation enables efficient rendering by maintaining a per-query top-K map that approximates nearest neighbors under the same shading score, allowing GPU-friendly, fixed-size local computation. We update this list using our top-K propagation scheme inspired by jump flooding, augmented with stochastic injection to provide probabilistic global coverage. Training follows a GPU-first pipeline with gradient-weighted initialization, Adam optimization, and adaptive budget control through densification and pruning. Across standard benchmarks, SAD consistently outperforms Image-GS and Instant-NGP at matched bitrate. On Kodak, SAD reaches 46.0 dB PSNR with 2.2 s encoding time (vs. 28 s for Image-GS), and delivers 4-19x end-to-end training speedups over state-of-the-art baselines. We demonstrate the effectiveness of SAD by showcasing the seamless integration with differentiable pipelines for forward and inverse problems, efficiency of fast random access and compact storage. Code will be released upon publication.
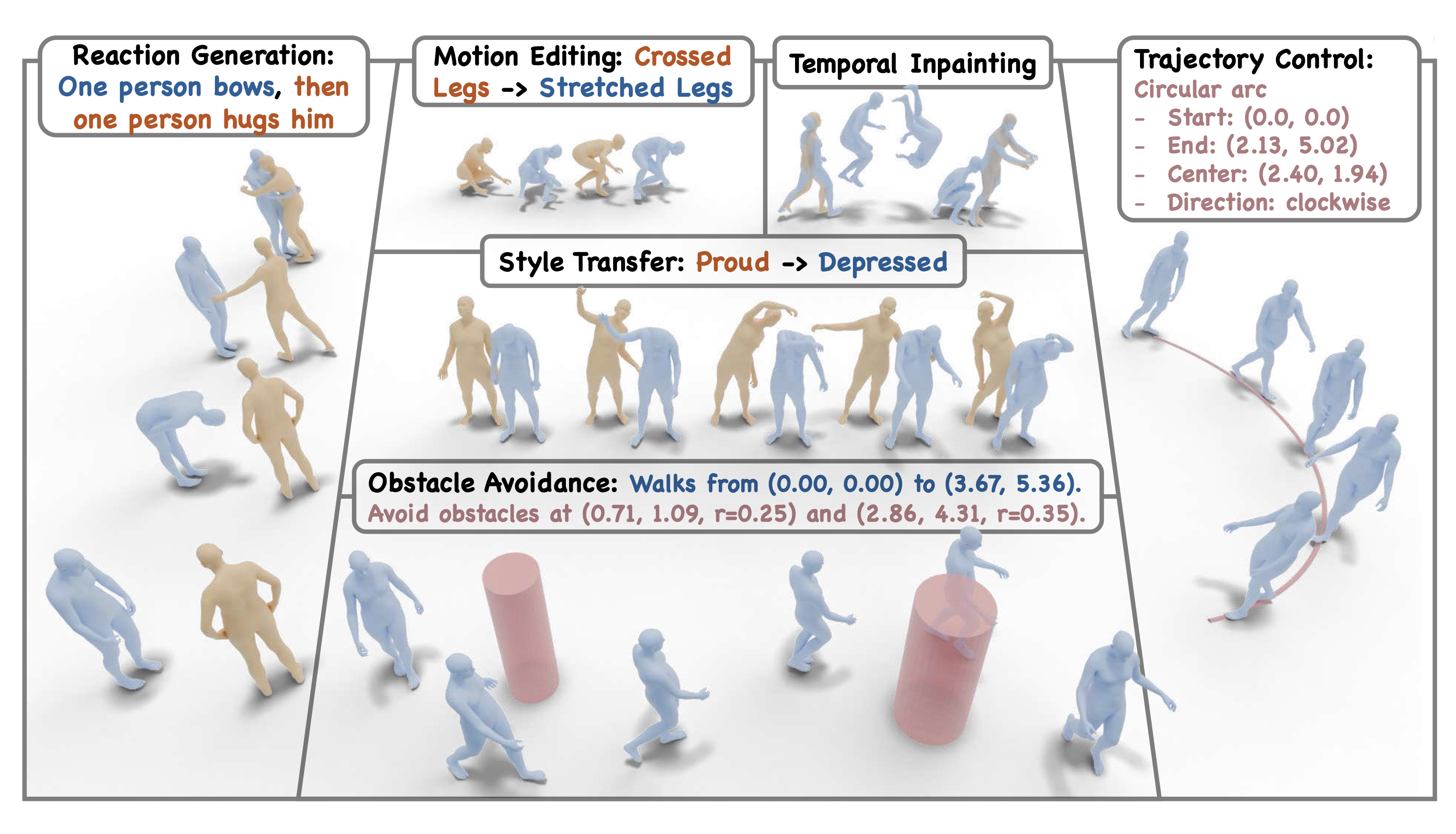
UMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Xiaoyan Cong*, Zekun Li*, Zhiyang Dou, Hongyu Li, Omid Taheri, Chuan Guo, Abhay Mittal, Sizhe An, Taku Komura, Wojciech Matusik, Michael J. Black, Srinath Sridhar.
ECCV 2026.
Xiaoyan Cong*, Zekun Li*, Zhiyang Dou, Hongyu Li, Omid Taheri, Chuan Guo, Abhay Mittal, Sizhe An, Taku Komura, Wojciech Matusik, Michael J. Black, Srinath Sridhar.
ECCV 2026.
- project page
- paper
- code (cs)
-
abstract
Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model.
GeoPT: Scaling Physics Simulation via Lifted Geometric Pre-Training
Haixu Wu*, Minghao Guo*, Zongyi Li, Zhiyang Dou, Mingsheng Long, Kaiming He, Wojciech Matusik.
ICML 2026.
Best Paper Award at the ICLR 2026 Workshop on Foundation Models for Science.
Haixu Wu*, Minghao Guo*, Zongyi Li, Zhiyang Dou, Mingsheng Long, Kaiming He, Wojciech Matusik.
ICML 2026.
Best Paper Award at the ICLR 2026 Workshop on Foundation Models for Science.
- project page
- paper
- code
-
abstract
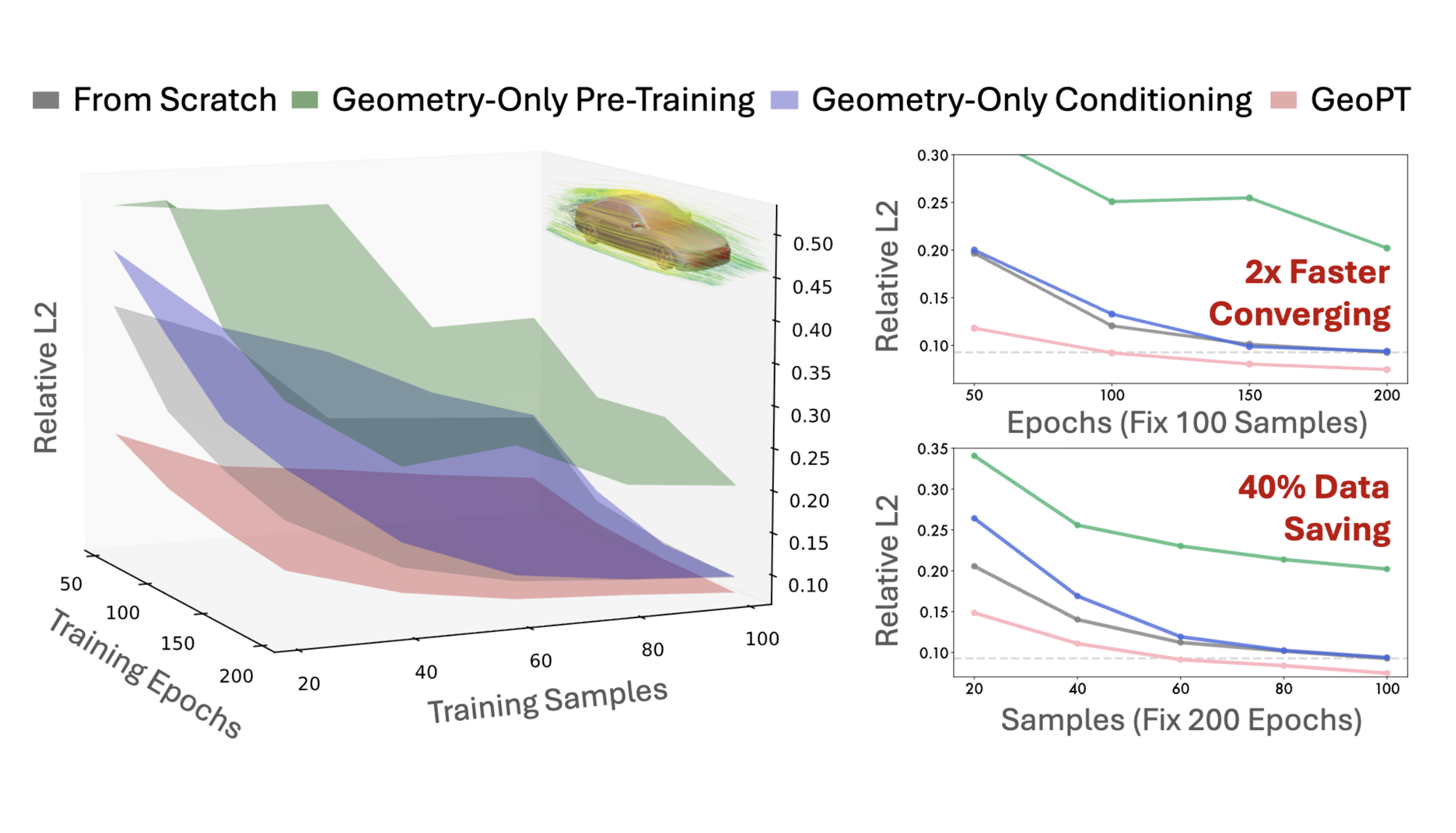
Neural simulators promise efficient surrogates for physics simulation, but scaling them is bottlenecked by the prohibitive cost of generating high-fidelity training data. Pre-training on off-the-shelf geometries offers a natural alternative, yet faces a fundamental gap: supervision on static geometry alone ignores dynamics and can lead to negative transfer on physics tasks. We present GeoPT, a unified pre-trained model for general physics simulation based on lifted geometric pre-training. The core idea is to augment geometry with synthetic dynamics, enabling dynamics-aware self-supervision without physics labels. Pre-trained on over one million samples, GeoPT consistently improves industrial-fidelity benchmarks spanning fluid mechanics for cars, aircraft, and ships, and solid mechanics in crash simulation, reducing labeled data requirements by 20-60% and accelerating convergence by 2x. These results show that lifting with synthetic dynamics bridges the geometry-physics gap, unlocking a scalable path for neural simulation.

MoSAT: Human Motion Generation from Spatial Audio and Textual Description
Shuyang Xu, Zhiyang Dou†§, Yiduo Hao, Minghao Guo, Liang Pan, Jingbo Wang, Cheng Lin, Yuan Liu, Wenping Wang, Chuang Gan, Mingmin Zhao, Wojciech Matusik, Taku Komura†.
§ Work done during Summer 2025.
Shuyang Xu, Zhiyang Dou†§, Yiduo Hao, Minghao Guo, Liang Pan, Jingbo Wang, Cheng Lin, Yuan Liu, Wenping Wang, Chuang Gan, Mingmin Zhao, Wojciech Matusik, Taku Komura†.
§ Work done during Summer 2025.
- project page (cs)
- paper (cs)
- code (cs)
-
abstract
Humans could naturally respond to both acoustic cues and semantic intent: spatial audio provides continuous, fine-grained spatiotemporal trajectories, whereas text anchors high-level semantics in discrete units. In this paper, we study the novel task of human motion synthesis jointly conditioned on spatial audio and natural language, a problem that has been largely overlooked in previous research. We introduce STAM, a dataset of motion sequences paired with spatial audio and detailed textual annotations whose rich vocabulary affords precise and nuanced specification of human motions. We present MoSAT, the first baseline to fuse spatial audio and text for fine-grained multimodal control of human motion synthesis. We employ a Motion RVQ-VAE to encode motions into a compact, expressive latent space, and a Spatial Audio VAE that efficiently models spatial audio characteristics. On top of these, an autoregressive transformer predicts human motion from coordinated spatial-audio and text embeddings, followed by residual refinement. Such a hierarchical design enhances temporally coherent and semantically aligned motion sequences. We also develop tri-modal evaluators for comprehensive evaluation on this new task. Extensive experiments show that MoSAT achieves the SOTA performance by leveraging spatial audio’s intrinsic motion-shaping properties alongside textual semantics, enabling precise and diverse motion in various scenarios. Our code and data will be released upon acceptance.

EgoReAct: Egocentric Video-Driven 3D Human Reaction Generation
Libo Zhang, Zekun Li, Tianyu Li, Zeyu Cao, Rui Xu, Xiao-Xiao Long, Wenjia Wang, Jingbo Wang, Yuan Liu, Wenping Wang, Daquan Zhou, Taku Komura, Zhiyang Dou†§.
§ Work done during Summer 2025.
Libo Zhang, Zekun Li, Tianyu Li, Zeyu Cao, Rui Xu, Xiao-Xiao Long, Wenjia Wang, Jingbo Wang, Yuan Liu, Wenping Wang, Daquan Zhou, Taku Komura, Zhiyang Dou†§.
§ Work done during Summer 2025.
- project page
- paper
- code (cs)
-
abstract
Humans exhibit adaptive, context-sensitive responses to egocentric visual input. However, faithfully modeling such reactions from egocentric video remains challenging due to the dual requirements of strictly causal generation and precise 3D spatial alignment. To tackle this problem, we first construct the Human Reaction Dataset (HRD) to address data scarcity and misalignment by building a spatially aligned egocentric video–reaction dataset, as existing datasets (e.g., ViMo) suffer from significant spatial inconsistency between the egocentric video and reaction motion, e.g., dynamically moving motions are always paired with fixed-camera videos. Leveraging HRD, we present EgoReAct, the first autoregressive framework that generates 3D-aligned human reaction motions from egocentric video streams in real-time. We first compress the reaction motion into a compact yet expressive latent space via a Vector Quantised-Variational AutoEncoder and then train a Generative Pre-trained Transformer for reaction generation from the visual input. EgoReAct incorporates 3D dynamic features, i.e., metric depth, and head dynamics during the generation, which effectively enhance spatial grounding. Extensive experiments demonstrate that EgoReAct achieves remarkably higher realism, spatial consistency, and generation efficiency compared with prior methods, while maintaining strict causality during generation. We will release code, models, and data upon acceptance.

Switch-JustDance: Benchmarking Whole-Body Motion Tracking Policies Using a Commercial
Console Game
Jeonghwan Kim*, Wontaek Kim*, Yidan Lu*, Jin Cheng*, Fatemeh Zargarbashi*, Zicheng Zeng*, Zekun Qi*, Zhiyang Dou, Nitish Sontakke, Donghoon Baek, Sehoon Ha, Tianyu Li.
CVPR Findings 2026.
Jeonghwan Kim*, Wontaek Kim*, Yidan Lu*, Jin Cheng*, Fatemeh Zargarbashi*, Zicheng Zeng*, Zekun Qi*, Zhiyang Dou, Nitish Sontakke, Donghoon Baek, Sehoon Ha, Tianyu Li.
CVPR Findings 2026.
- project page
- paper
-
abstract
Recent advances in whole-body robot control have enabled humanoid and legged robots to perform increasingly agile and coordinated motions. However, standardized benchmarks for evaluating these capabilities in real-world settings, and in direct comparison to humans, remain scarce. Existing evaluations often rely on pre-collected human motion datasets or simulation-based experiments, which limit reproducibility, overlook hardware factors, and hinder fair human–robot comparisons. We present Switch-JustDance, a low-cost and reproducible benchmarking pipeline that leverages motion-sensing console games, Just Dance on the Nintendo Switch, to evaluate robot whole-body control. Using Just Dance on the Nintendo Switch as a representative platform, Switch-JustDance converts in-game choreography into robot-executable motions through streaming, motion reconstruction, and motion retargeting modules and enables users to evaluate controller performance through the game's built-in scoring system. We first validate the evaluation properties of Just Dance, analyzing its reliability, validity, sensitivity, and potential sources of bias. Our results show that the platform provides consistent and interpretable performance measures, making it a suitable tool for benchmarking embodied AI. Building on this foundation, we benchmark three state-of-the-art humanoid whole-body controllers on hardware and provide insights into their relative strengths and limitations.

PointNSP: Autoregressive 3D Point Cloud Generation with Next-Scale Level-of-Detail
Prediction
Ziqiao Meng, Qichao Wang, Zhiyang Dou, Zixing Song, Zhipeng Zhou, Irwin King, Peilin Zhao.
CVPR 2026.
Ziqiao Meng, Qichao Wang, Zhiyang Dou, Zixing Song, Zhipeng Zhou, Irwin King, Peilin Zhao.
CVPR 2026.
- paper
- project page
- code
-
abstract
Autoregressive point cloud generation has long lagged behind diffusion-based approaches in quality. The performance gap stems from the fact that autoregressive models impose an artificial ordering on inherently unordered point sets, forcing shape generation to proceed as a sequence of local predictions. This sequential bias reinforces short-range continuity but limits the model's ability to capture long-range dependencies, thereby weakening its capacity to enforce global structural properties such as symmetry, geometric consistency, and large-scale spatial regularities. Inspired by the level-of-detail (LOD) principle in shape modeling, we propose PointNSP, a coarse-to-fine generative framework that preserves global shape structure at low resolutions and progressively refines fine-grained geometry at higher scales through a next-scale prediction paradigm. This multi-scale factorization aligns the autoregressive objective with the permutation-invariant nature of point sets, enabling rich intra-scale interactions while avoiding brittle fixed orderings. Strictly following the baseline experimental setups, empirical results on ShapeNet benchmark demonstrate that PointNSP achieves state-of-the-art (SOTA) generation quality for the first time within the autoregressive paradigm. Moreover, it surpasses strong diffusion-based baselines in parameter, training, and inference efficiency. Finally, under dense generation with 8,192 points, PointNSP's advantages become even more pronounced, highlighting its strong scalability potential.

MeshMosaic: Scaling Artist Mesh Generation via Local-to-Global Assembly
Rui Xu, Tianyang Xue, Qiujie Dong, Le Wan, Zhe Zhu, Peng Li, Zhiyang Dou, Cheng Lin, Shiqing Xin, Yuan Liu, Wenping Wang, Taku Komura.
CVPR 2026.
Rui Xu, Tianyang Xue, Qiujie Dong, Le Wan, Zhe Zhu, Peng Li, Zhiyang Dou, Cheng Lin, Shiqing Xin, Yuan Liu, Wenping Wang, Taku Komura.
CVPR 2026.
- project page
- paper
-
abstract
Scaling artist-designed meshes to high triangle numbers remains challenging for autoregressive generative models. Existing transformer-based methods suffer from long-sequence bottlenecks and limited quantization resolution, primarily due to the large number of tokens required and constrained quantization granularity. These issues prevent faithful reproduction of fine geometric details and structured density patterns. We introduce MeshMosaic, a novel local-to-global framework for artist mesh generation that scales to over 100K triangles—substantially surpassing prior methods, which typically handle only around 8K faces. MeshMosaic first segments shapes into patches, generating each patch autoregressively and leveraging shared boundary conditions to promote coherence, symmetry, and seamless connectivity between neighboring regions. This strategy enhances scalability to high-resolution meshes by quantizing patches individually, resulting in more symmetrical and organized mesh density and structure. Extensive experiments across multiple public datasets demonstrate that MeshMosaic significantly outperforms state-of-the-art methods in both geometric fidelity and user preference, supporting superior detail representation and practical mesh generation for real-world applications.
Text2Interact: High-Fidelity and Diverse Text-to-Two-Person Interaction Generation
Qingxuan Wu, Zhiyang Dou, Chuan Guo, Yiming Huang, Qiao Feng, Bing Zhou, Jian Wang, Lingjie Liu.
ICLR 2026.
Qingxuan Wu, Zhiyang Dou, Chuan Guo, Yiming Huang, Qiao Feng, Bing Zhou, Jian Wang, Lingjie Liu.
ICLR 2026.
- project page
- paper
- code
-
abstract
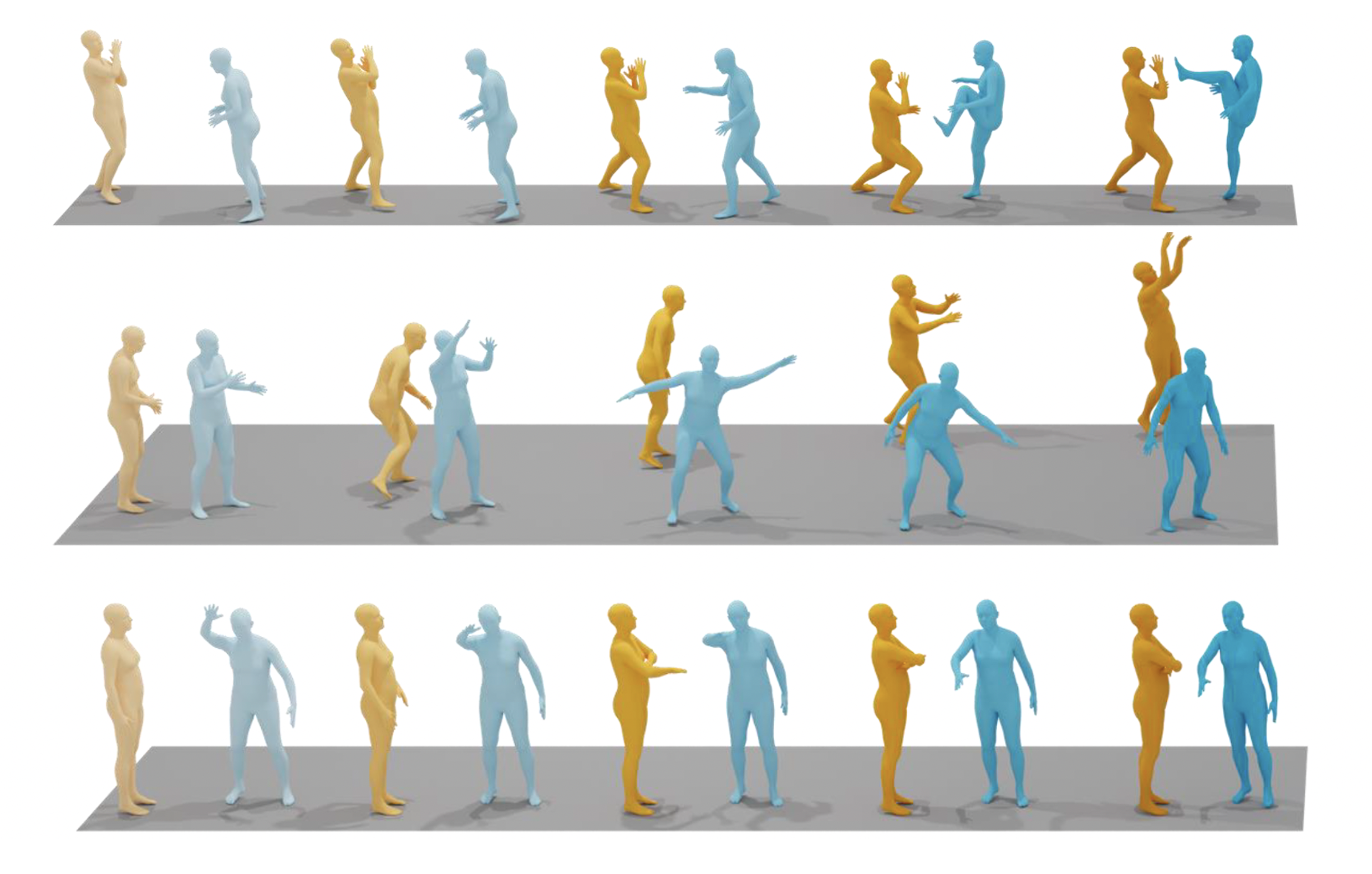
Generating realistic and diverse human-human interactions from text remains a fundamental but challenging problem in vision, graphics, and robotics. Current approaches face two main limitations: (i) interaction synthesis requires both high-quality individual motion and precise spatiotemporal coordination, yet existing datasets are too small to support such complexity, limiting generalization; and (ii) complex interactions often demand detailed textual descriptions, but sentence-level embeddings fail to capture fine-grained semantics. We address these issues with two contributions. First, we introduce InterCompose, a scalable data synthesis framework that combines the general knowledge of large language models with strong single-person motion priors to generate high-quality two-person interactions beyond existing distributions. Second, we propose Text2Interact, which employs word-level attention for fine-grained text-motion alignment and an adaptive supervision signal that dynamically weights body parts based on interaction context to enhance realism. Extensive experiments demonstrate that our approach substantially improves motion diversity, semantic alignment, and realism over state-of-the-art baselines. Our code and models will be released for reproducibility.
TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation
Hongyu Zhang, Yufan Deng, Zilin Pan, Peng-Tao Jiang, Bo Li, Qibin Hou, Zhen Dong, Zhiyang Dou, Daquan Zhou.
ICLR 2026.
Hongyu Zhang, Yufan Deng, Zilin Pan, Peng-Tao Jiang, Bo Li, Qibin Hou, Zhen Dong, Zhiyang Dou, Daquan Zhou.
ICLR 2026.
- paper
-
abstract
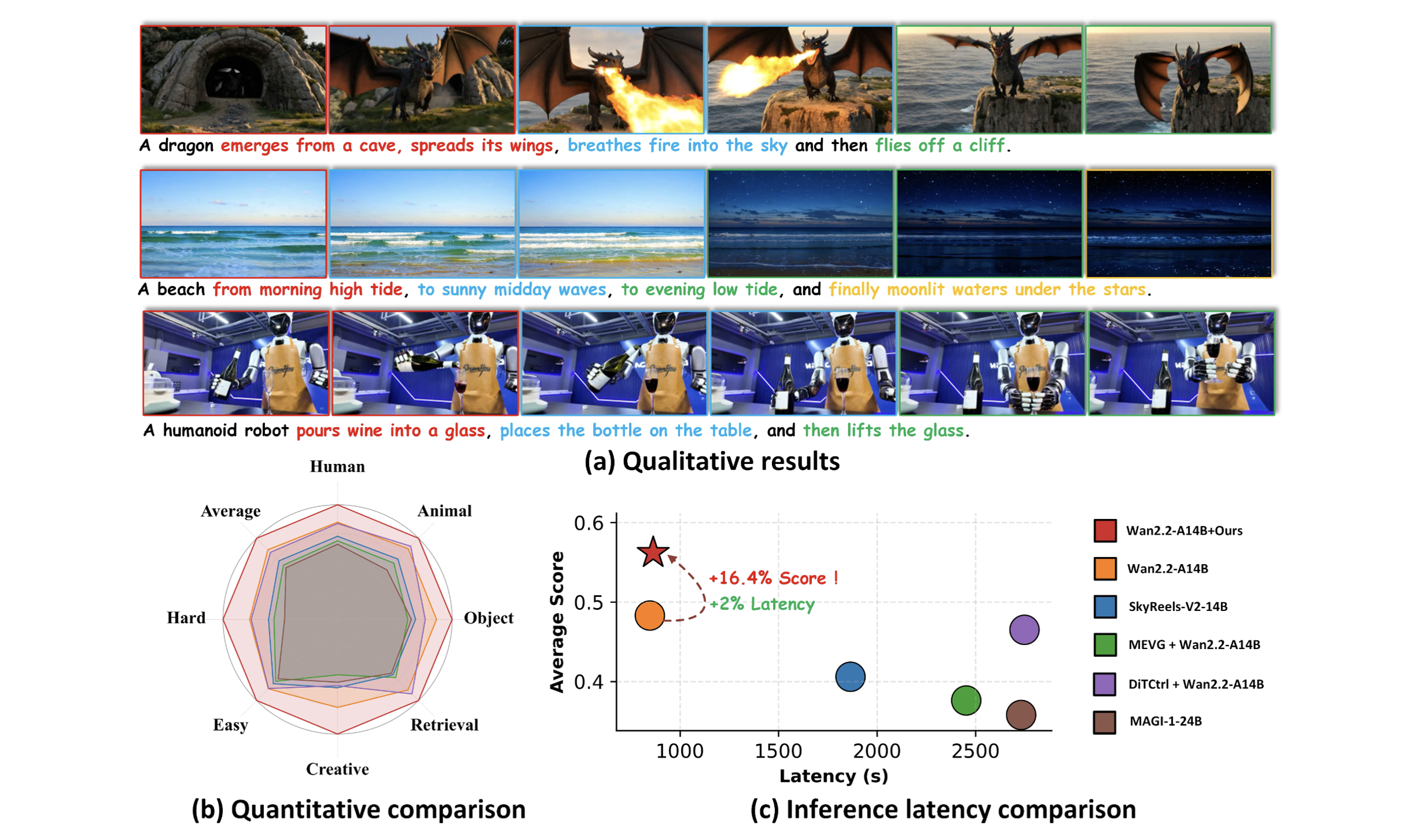
Generating high-quality videos from complex temporal descriptions, which refer to prompts containing multiple sequential actions, remains a significant challenge. Existing methods are constrained by an inherent trade-off: using multiple short prompts fed sequentially into the model improves action fidelity but compromises temporal consistency, while a single complex prompt preserves consistency at the cost of prompt following capability. We attribute this problem to two primary causes: temporal misalignment between video content and the prompt, and conflicting attention coupling between motion-related visual objects and their associated text conditions. To address these challenges, we propose a novel, training-free attention mechanism, Temporal-wise Separable Attention (TS-Attn), which dynamically rearranges attention distribution to ensure temporal awareness and global coherence in multi-event scenarios. TS-Attn can be seamlessly integrated into various pre-trained text-to-video models, boosting StoryEval-Bench scores by 33.5% and 16.4% on Wan2.1-T2V-14B and Wan2.2-T2V-A14B with only a 2% increase in inference time. It also supports plug-and-play usage across models for multi-event image-to-video generation. The source code and video demos are available in the supplementary materials.

PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Zhe Zhu, Le Wan, Rui Xu, Yiheng Zhang, Honghua Chen, Zhiyang Dou, Cheng Lin, Yuan Liu, Mingqiang Wei.
ICLR 2026.
Zhe Zhu, Le Wan, Rui Xu, Yiheng Zhang, Honghua Chen, Zhiyang Dou, Cheng Lin, Yuan Liu, Mingqiang Wei.
ICLR 2026.
- project page
- paper
- code
-
abstract
Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a "Segment-Every-Part" mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding.
Neural Modular World Model
Minghao Guo, Zhiyang Dou, Chong Zeng, Wojciech Matusik.
ICML 2025 Workshop on Building Physically Plausible World Models.
Minghao Guo, Zhiyang Dou, Chong Zeng, Wojciech Matusik.
ICML 2025 Workshop on Building Physically Plausible World Models.
- paper
-
abstract
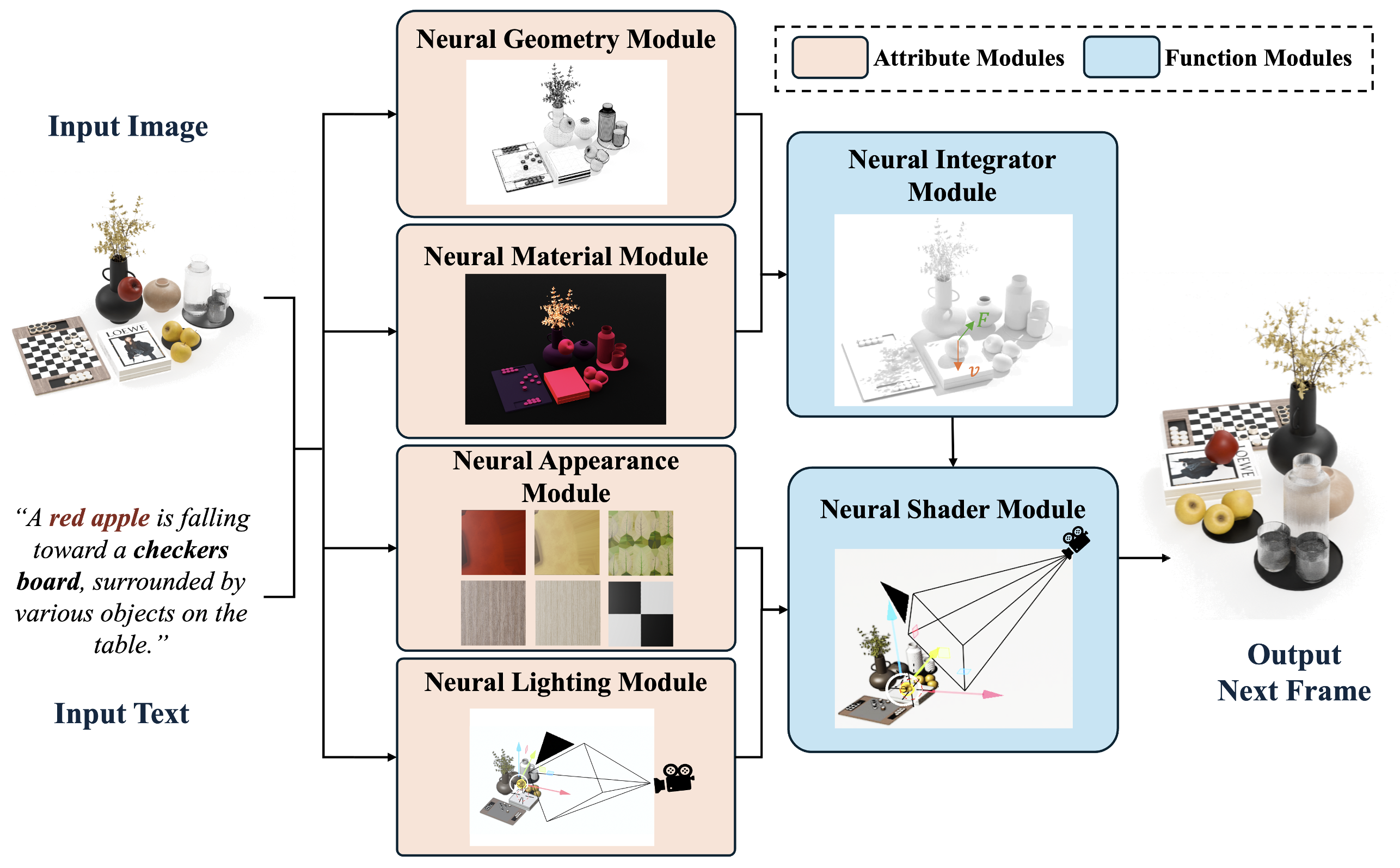
We introduce the Neural Modular World Model, a graphics-inspired framework that decomposes learned world models into two interoperable layers: Attribute modules infer scene-specific descriptors--geometry, material, appearance, and illumination--via either explicit assets or compact neural fields. Function modules supply reusable, content-agnostic operators for physics integration and image synthesis. This attribute-function split combines the expressive power of large generative networks with the physical guarantees and interpretability of classical simulation, yielding (i) photorealistic and physically accurate predictions, (ii) fine-grained controllability through independent module dials, and (iii) precise error attribution for system identification and targeted debugging. We anticipate that the modular structure will unlock orthogonal scaling, letting geometry, physics, and rendering grow independently, rather than balloon together in a single monolithic network. These properties make Neural Modular World Model a practical blueprint for building planet-scale, physically faithful world models.

Wonder3D++: Cross-domain Diffusion for High-fidelity 3D Generation from a Single
Image
Yuxiao Yang*, Xiaoxiao Long*, Zhiyang Dou, Cheng Lin, Yuan Liu, Qingsong Yan, Yuexin Ma, Haoqian Wang, Zhiqiang Wu, Wei Yin.
TPAMI 2025.
Yuxiao Yang*, Xiaoxiao Long*, Zhiyang Dou, Cheng Lin, Yuan Liu, Qingsong Yan, Yuexin Ma, Haoqian Wang, Zhiqiang Wu, Wei Yin.
TPAMI 2025.
- project page (cs)
- paper
- code (cs)
-
abstract
In this work, we introduce Wonder3D++, a novel method for efficiently generating high-fidelity textured meshes from single-view images. Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details. To holistically improve the quality, consistency, and efficiency of single-view reconstruction tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure the consistency of generation, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a cascaded 3D mesh extraction algorithm that drives high-quality surfaces from the multi-view 2D representations in only about 3 minute in a coarse-to-fine manner. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and good efficiency compared to prior works.
🎧 MOSPA: Spatial Audio-Driven Human Motion Generation
Shuyang Xu*, Zhiyang Dou*†, Mingyi Shi, Liang Pan, Leo Ho, Jingbo Wang, Yuan Liu, Cheng Lin, Yuexin Ma, Wenping Wang†, Taku Komura†.
NeurIPS 2025 (Spotlight). 13% of accepted papers.
Shuyang Xu*, Zhiyang Dou*†, Mingyi Shi, Liang Pan, Leo Ho, Jingbo Wang, Yuan Liu, Cheng Lin, Yuexin Ma, Wenping Wang†, Taku Komura†.
NeurIPS 2025 (Spotlight). 13% of accepted papers.
- project page
- paper
- code
-
abstract
Enabling virtual humans to dynamically and realistically respond to diverse auditory stimuli remains a key challenge in character animation, demanding the integration of perceptual modeling and motion synthesis. Despite its significance, this task remains largely unexplored. Most previous works have primarily focused on mapping modalities such as language, audio, and music to human motion generation. As of yet, these models typically overlook the impact of spatial features encoded in spatial audio signals on human motion. To bridge this gap and enable high-quality modeling of human movements in response to spatial audio, we introduce the Spatial Audio-Driven Human Motion (SAM) dataset, which contains diverse and high-quality spatial audio and motion data. Furthermore, we develop a diffusion-based generative framework named MOSPA to capture the relationship between body motion and spatial audio with an effective fusion mechanism. After training, MOSPA could generate diverse realistic human motions conditioned on varying spatial audio inputs. We conducted extensive experiments to validate our method, which achieves state-of-the-art performance on this task. Our model and dataset will be open-sourced upon acceptance. Refer to our supplementary video for more details.
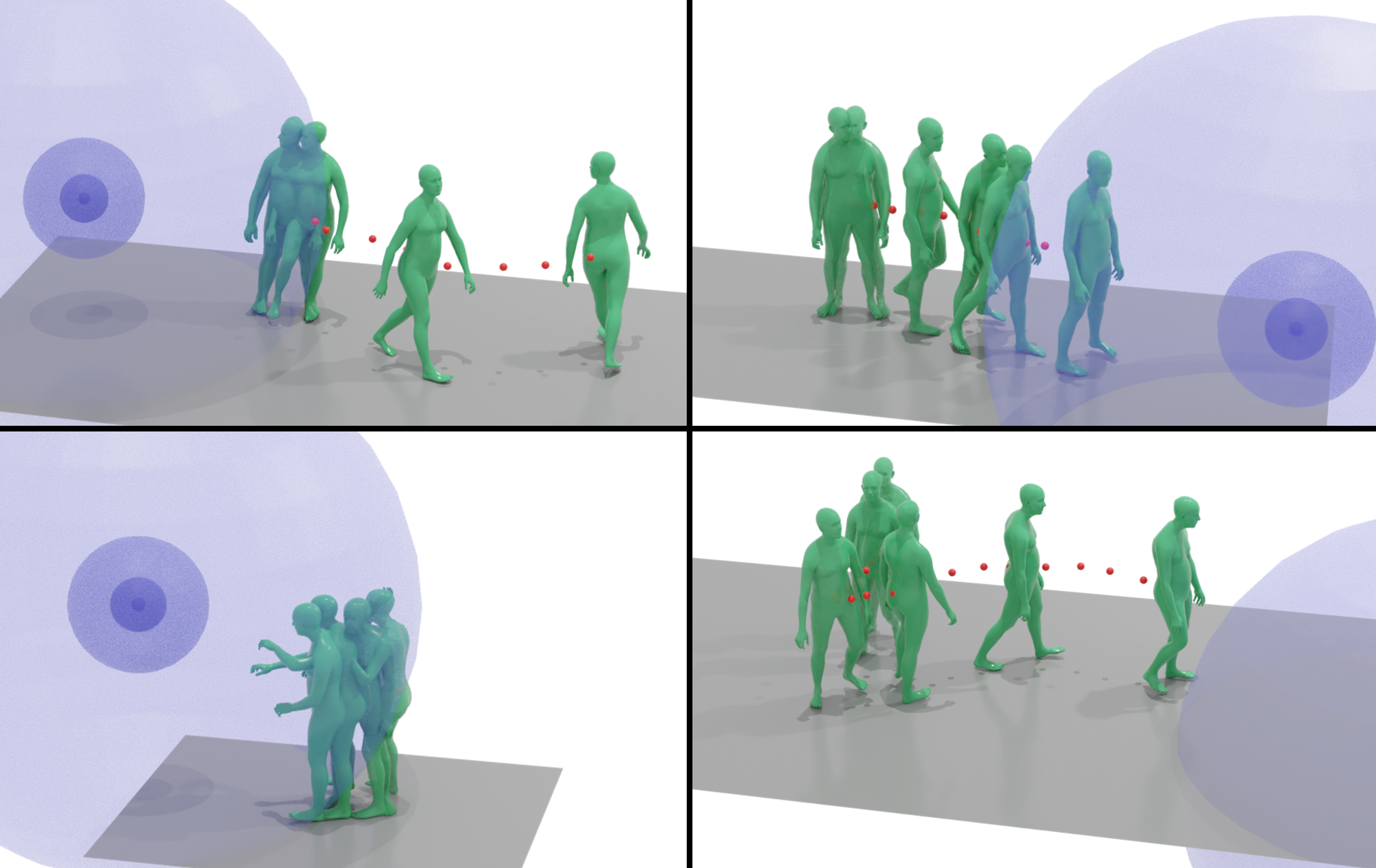
CoDA: Coordinated Diffusion Noise Optimization for Whole-Body Manipulation of Articulated
Objects
Huaijin Pi, Zhi Cen, Zhiyang Dou, Taku Komura.
NeurIPS 2025.
Huaijin Pi, Zhi Cen, Zhiyang Dou, Taku Komura.
NeurIPS 2025.
- project page
- paper
-
abstract
Synthesizing whole-body manipulation of articulated objects, including body motion, hand motion, and object motion, is a critical yet challenging task with broad applications in virtual humans and robotics. The core challenges are twofold. First, achieving realistic whole-body motion requires tight coordination between the hands and the rest of the body, as their movements are interdependent during manipulation. Second, articulated object manipulation typically involves high degrees of freedom and demands higher precision, often requiring the fingers to be placed at specific regions to actuate movable parts. To address these challenges, we propose a novel coordinated diffusion noise optimization framework. Specifically, we perform noise-space optimization over three specialized diffusion models for the body, left hand, and right hand, each trained on its own motion dataset to improve generalization. Coordination naturally emerges through gradient flow along the human kinematic chain, allowing the global body posture to adapt in response to hand motion objectives with high fidelity. To further enhance precision in hand-object interaction, we adopt a unified representation based on basis point sets (BPS), where end-effector positions are encoded as distances to the same BPS used for object geometry. This unified representation captures fine-grained spatial relationships between the hand and articulated object parts, and the resulting trajectories serve as targets to guide the optimization of diffusion noise, producing highly accurate interaction motion. We conduct extensive experiments demonstrating that our method outperforms existing approaches in motion quality and physical plausibility, and enables various capabilities such as object pose control, simultaneous walking and manipulation, and whole-body generation from hand-only data.

PhysCtrl: Generative Physics for Controllable and Physics-Grounded Video Generation
Chen Wang*, Chuhao Chen*, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, Lingjie Liu.
NeurIPS 2025.
Chen Wang*, Chuhao Chen*, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, Lingjie Liu.
NeurIPS 2025.
- project page
- paper
-
abstract
Existing video generation models excel at producing photo-realistic videos from text or images, but often lack physical plausibility and 3D controllability. To overcome these limitations, we introduce PhysCtrl, a novel framework for physics-grounded image-to-video generation with physical parameters and force control. At its core is a generative physics network that learns the distribution of physical dynamics across four materials (elastic, sand, plasticine, and rigid) via a diffusion model conditioned on physics parameters and applied forces. We represent physical dynamics as 3D point trajectories and train on a large-scale synthetic dataset of 550K animations generated by physics simulators. We enhance the diffusion model with a novel spatiotemporal attention block that emulates particle interactions and incorporates physics-based constraints during training to enforce physical plausibility. Experiments show that PhysCtrl generates realistic, physics-grounded motion trajectories which, when used to drive image-to-video models, yield high-fidelity, controllable videos that outperform existing methods in both visual quality and physical plausibility.

TrackingWorld: World-centric Monocular 3D Tracking of Almost All Pixels
Jiahao Lu, Weitao Xiong, Jiacheng Deng, Peng Li, Tianyu Huang, Zhiyang Dou, Cheng Lin, Sai-Kit Yeung, Yuan Liu.
NeurIPS 2025.
Jiahao Lu, Weitao Xiong, Jiacheng Deng, Peng Li, Tianyu Huang, Zhiyang Dou, Cheng Lin, Sai-Kit Yeung, Yuan Liu.
NeurIPS 2025.
- project page (cs)
- paper (cs)
- code
-
abstract
Monocular 3D tracking aims to capture the long-term motion of pixels in 3D space from a single monocular video and has witnessed rapid progress in recent years. However, we argue that the existing monocular 3D tracking methods still fall short in separating the camera motion from foreground dynamic motion and cannot densely track newly emerging dynamic subjects in the videos. To address these two limitations, we propose TrackingWorld, a novel pipeline for dense 3D tracking of almost all pixels within a world-centric 3D coordinate system. First, we introduce a tracking upsampler that efficiently lifts the arbitrary sparse 2D tracks into dense 2D tracks. Then, to generalize the current tracking methods to newly emerging objects, we apply the upsampler to all frames and reduce the redundancy of 2D tracks by eliminating the tracks in overlapped regions. Finally, we present an efficient optimization-based framework to back-project dense 2D tracks into world-centric 3D trajectories by estimating the camera poses and the 3D coordinates of these 2D tracks. Extensive evaluations on both synthetic and real-world datasets demonstrate that our system achieves accurate and dense 3D tracking in a world-centric coordinate frame.

SyncHuman: Synchronizing 2D and 3D Diffusion Models for Single-view Human
Reconstruction
Wenyue Chen, Peng Li, Wangguandong Zheng, Chengfeng Zhao, Mengfei Li, Yaolong Zhu, Zhiyang Dou, Ronggang Wang, Yuan Liu.
NeurIPS 2025.
Wenyue Chen, Peng Li, Wangguandong Zheng, Chengfeng Zhao, Mengfei Li, Yaolong Zhu, Zhiyang Dou, Ronggang Wang, Yuan Liu.
NeurIPS 2025.
- project page (cs)
- paper (cs)
- code (cs)
-
abstract
Photorealistic 3D full-body human reconstruction from a single image is a critical yet challenging task for applications in films and video games due to inherent ambiguities and severe self-occlusions. While recent approaches leverage SMPL estimation and SMPL-conditioned image diffusion models to hallucinate novel views, they suffer from inaccurate 3D priors estimated from SMPL meshes and have difficulty in handling difficult human poses and reconstructing fine details.In this paper, we propose SyncHuman, a novel framework that combines 2D multiview diffusion and 3D native diffusion for the first time, enabling high-quality clothed human mesh reconstruction from single-view images even under challenging human poses.Multiview diffusion excels at capturing fine 2D details but struggles with structural consistency, whereas 3D native diffusion generates coarse yet structurally consistent 3D shapes. By integrating the complementary strengths of these two approaches, we develop a more effective generation framework. Specifically, we first jointly fine-tune the multiview diffusion model and the 3D native diffusion model with proposed pixel-aligned 2D-3D synchronization attention to produce geometrically aligned 3D shapes and 2D multiview images. To further improve details, we introduce a feature injection mechanism that lifts fine details from 2D multiview images onto the aligned 3D shapes, enabling accurate and high-fidelity reconstruction.Extensive experiments demonstrate that SyncHuman achieves robust and photorealistic 3D human reconstruction, even for images with challenging poses. Our method outperforms baseline methods in geometric accuracy and visual fidelity, demonstrating a promising direction for future 3D generation models.

CFC: Simulating Character-Fluid Coupling using a Two-Level World Model
Zhiyang Dou*, Chen Peng*, Xinyu Lu, Xiaohan Ye, Lixing Fang, Yuan Liu, Wenping Wang, Chuang Gan, Lingjie Liu, Taku Komura†.
ACM Transactions on Graphics (SIGGRAPH Asia 2025).
Zhiyang Dou*, Chen Peng*, Xinyu Lu, Xiaohan Ye, Lixing Fang, Yuan Liu, Wenping Wang, Chuang Gan, Lingjie Liu, Taku Komura†.
ACM Transactions on Graphics (SIGGRAPH Asia 2025).
- project page
- paper
- slide
-
abstract
Humans possess the ability to master a wide range of motor skills, using which they can quickly and flexibly adapt to the surrounding environment. Despite recent progress in replicating such versatile human motor skills, existing research often oversimplifies or inadequately captures the complex interplay between human body movements and highly dynamic environments, such as interactions with fluids. In this paper, we present a world model for Character-Fluid Coupling (CFC) for simulating human-fluid interactions via two-way coupling. We introduce a two-level world model which consists of a Physics-Informed Neural Network (PINN)-based model for fluid dynamics and a rigid body world model capturing body dynamics under various external forces. This hierarchical world model adeptly predicts the dynamics of fluid and its influence on rigid bodies, sidestepping the computational burden of fluid simulation and providing policy gradients for efficient policy training. Once trained, our system can control characters to complete high-level tasks while adaptively responding to environmental changes. We also present that the fluid initiates emergent behaviors of the characters, enhancing motion diversity and interactivity. Extensive experiments underscore the effectiveness of CFC, demonstrating its ability to produce high-quality, realistic human-fluid interaction animations.

KISSColor: Kinetic and Intuitive Stroke Stretching for Vector Drawing Colorization
Yiming Dong*, Hongxu Xin*, Zhiyang Dou†, Rui Xu, Yuan Liu, Shuangmin Chen, Shiqing Xin, Changhe Tu†, Taku Komura, Wenping Wang.
ACM Transactions on Graphics (SIGGRAPH Asia 2025).
Yiming Dong*, Hongxu Xin*, Zhiyang Dou†, Rui Xu, Yuan Liu, Shuangmin Chen, Shiqing Xin, Changhe Tu†, Taku Komura, Wenping Wang.
ACM Transactions on Graphics (SIGGRAPH Asia 2025).
- project page (cs)
- paper
- code
-
abstract
Hand-drawn vector sketches often contain implied lines, imprecise intersections, and unintended gaps, making it challenging to identify closed regions for colorization. These challenges become more pronounced as the number of strokes increases. In this paper, we present KISSColor, a novel method for inferring users' intended closed regions. Specifically, we propose intuitive stroke stretching by extending open strokes along tangent isolines of winding number fields, which provably form geometrically aligned closed regions. Extending all open strokes can lead to overly fragmented regions due to redundant intersections. While a Mixed Integer Programming (MIP) formulation helps reduce redundancy, it is computationally expensive. To improve efficiency, we introduce kinetic stroke stretching, which grows all strokes simultaneously and prioritizes early intersections using a kinetic data structure. This approach preserves stylistic ambiguity for lines requiring long extensions. Based on the growth results, redundant regions are suppressed to minimize fragmentation. We conduct extensive experiments demonstrating the effectiveness of KISSColor, which generates more intuitive partitions, especially for imprecise sketches. Our code and data will be released upon publication.

Motion2Motion: Cross-topology Motion Retargeting with Sparse Correspondence
Ling-Hao Chen, Yuhong Zhang, Zixin Yin, Zhiyang Dou, Xin Chen, Jingbo Wang, Taku Komura, Lei Zhang.
SIGGRAPH Asia 2025.
Ling-Hao Chen, Yuhong Zhang, Zixin Yin, Zhiyang Dou, Xin Chen, Jingbo Wang, Taku Komura, Lei Zhang.
SIGGRAPH Asia 2025.
- project page (cs)
- paper (cs)
-
abstract
This work studies the challenge of retargeting animations between characters whose skeletal topologies differ substantially. While many techniques have advanced retargeting techniques in decades, retargeting motions across diverse topologies remains less-explored. The primary obstacle lies in the inherent topological inconsistency between source and target skeletons, which restricts the establishment of straightforward one-to-one bone correspondences. Besides, the current lack of large-scale paired motion datasets spanning different topological structures severely constrains the development of data-driven approaches. To address these limitations, we introduce Motion2Motion, a novel, training-free framework. Simply yet effectively, Motion2Motion works with only one or a few example motions on the target skeleton, by accessing a sparse set of bone correspondences between the source and target skeletons. Through comprehensive qualitative and quantitative evaluations, we demonstrate that Motion2Motion achieves efficient and reliable performance in both similar-skeleton and cross-species skeleton retargeting scenarios. The practical utility of our approach is further evidenced by its successful integration in downstream applications and user interfaces, highlighting its potential for industrial applications. Code and data will be publicly accessible.

SymBridge: A Human-in-the-Loop Cyber-Physical Interactive System for Adaptive Human-Robot
Symbiosis
Haoran Chen*, Yiteng Xu*, Yiming Ren, Yaoqin Ye, Xinran Li, Ning Ding, Yuxuan Wu, Yaoze Liu, Peishan Cong, Ziyi Wang, Bushi Liu, Yuhan Chen, Zhiyang Dou, Xiaokun Leng, Manyi Li, Yuexin Ma, Changhe Tu.
SIGGRAPH Asia 2025.
Haoran Chen*, Yiteng Xu*, Yiming Ren, Yaoqin Ye, Xinran Li, Ning Ding, Yuxuan Wu, Yaoze Liu, Peishan Cong, Ziyi Wang, Bushi Liu, Yuhan Chen, Zhiyang Dou, Xiaokun Leng, Manyi Li, Yuexin Ma, Changhe Tu.
SIGGRAPH Asia 2025.
- project page (cs)
- paper (cs)
-
abstract
The development of intelligent robots seeks to seamlessly integrate them into the human world, providing assistance and companionship in daily life and work, with the ultimate goal of achieving human-robot symbiosis. This requires robots with intelligent interaction abilities to work naturally and effectively with humans. However, current robotic simulators fail to support real human participation, limiting their ability to provide authentic interaction experiences and gather valuable human feedback essential for enhancing robotic capabilities. In this paper, we introduce SymBridge, the first human-in-the-loop cyber-physical interactive system designed to enable the safe and efficient development, evaluation, and optimization of human-robot interaction methods. Specifically, we employ augmented reality technology to enable real humans to interact with virtual robots in physical environments, creating an authentic interactive experience. Building on this, we propose a novel robotic interaction model that generates responsive, precise robot actions in real time through continuous human behavior observation. The model incorporates multi-resolution human motion features and environmental affordances, ensuring contextually adaptive robotic responses. Additionally, SymBridge enables continuous robot learning by collecting human feedback and dynamically adapting the robotic interaction model. By leveraging a carefully designed system architecture and modules, SymBridge builds a bridge between humans and robots, as well as between cyber and physical spaces, providing a natural and realistic online interaction experience while facilitating the continuous evolution of robotic intelligence. Extensive experiments, user studies, and real robot testing demonstrate the system's promising performance and highlight its potential to significantly advance research on human-robot symbiosis.
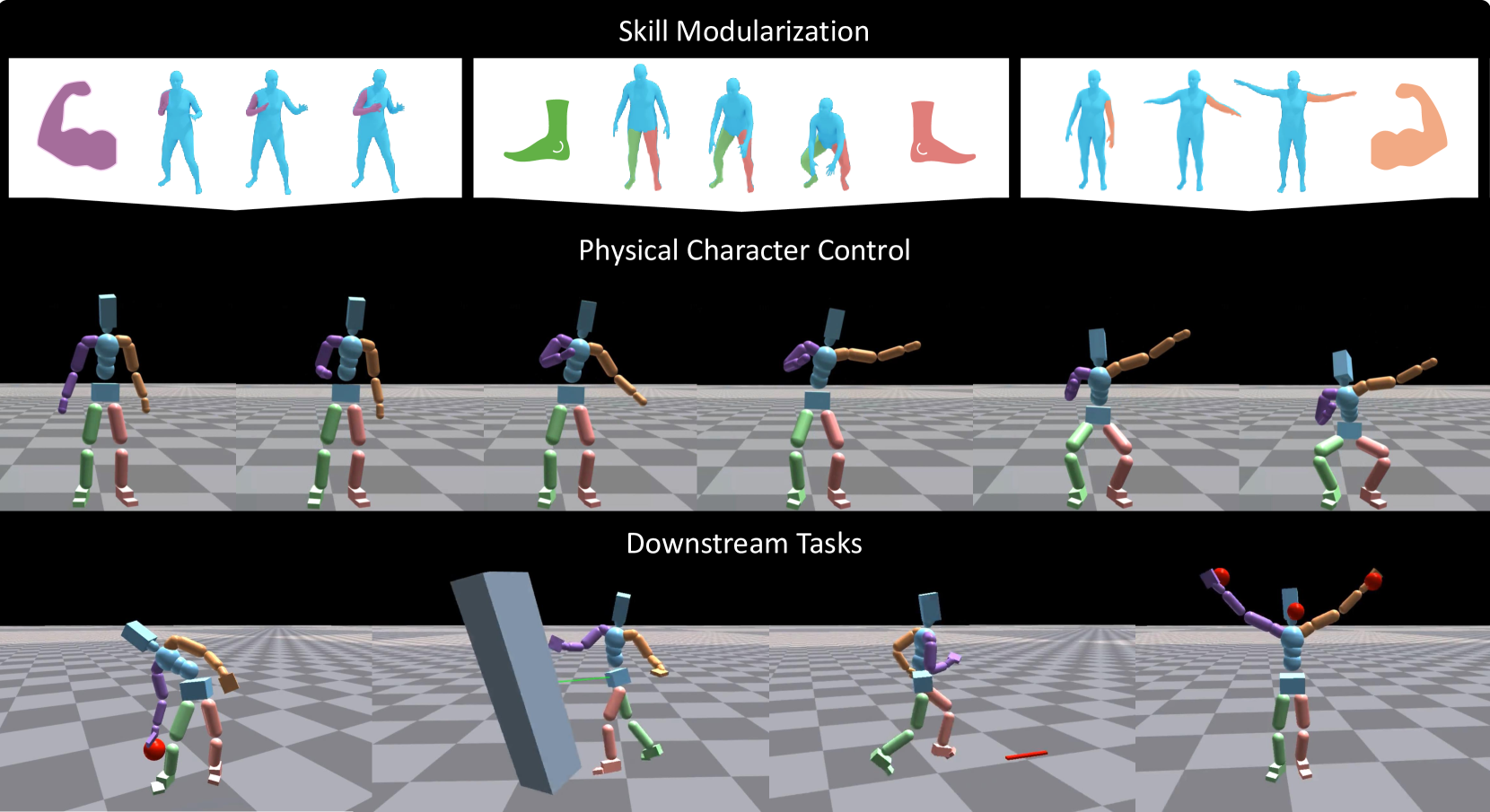
ModSkill: Physical Character Skill Modularization
Yiming Huang, Zhiyang Dou, Lingjie Liu.
ICCV 2025.
Yiming Huang, Zhiyang Dou, Lingjie Liu.
ICCV 2025.
- project page
- paper
-
abstract
Human motion is highly diverse and dynamic, posing challenges for imitation learning algorithms that aim to generalize motor skills for controlling simulated characters. Previous methods typically rely on a universal full-body controller for tracking reference motion (tracking-based model) or a unified full-body skill embedding space (skill embedding). However, these approaches often struggle to generalize and scale to larger motion datasets. In this work, we introduce a novel skill learning framework, ModSkill, that decouples complex full-body skills into compositional, modular skills for independent body parts. Our framework features a skill modularization attention layer that processes policy observations into modular skill embeddings that guide low-level controllers for each body part. We also propose an Active Skill Learning approach with Generative Adaptive Sampling, using large motion generation models to adaptively enhance policy learning in challenging tracking scenarios. Our results show that this modularized skill learning framework, enhanced by generative sampling, outperforms existing methods in precise full-body motion tracking and enables reusable skill embeddings for diverse goal-driven tasks.

SIMS: Simulating Stylized Human-Scene Interactions with Retrieval-Augmented Script
Generation
Wenjia Wang, Liang Pan, Zhiyang Dou, Zhouyingcheng Liao, Yuke Lou, Lei Yang, Jingbo Wang, Taku Komura.
ICCV 2025.
Wenjia Wang, Liang Pan, Zhiyang Dou, Zhouyingcheng Liao, Yuke Lou, Lei Yang, Jingbo Wang, Taku Komura.
ICCV 2025.
- project page
- paper
-
abstract
Simulating long-term human-scene interaction is a challenging yet fascinating task. Previous works have not effectively addressed the generation of long-term human scene interactions with detailed narratives for physics-based animation. This paper introduces a novel framework for the planning and controlling of long-horizon physical plausible human-scene interaction. On the one hand, films and shows with stylish human locomotions or interactions with scenes are abundantly available on the internet, providing a rich source of data for script planning. On the other hand, Large Language Models (LLMs) can understand and generate logical storylines. This motivates us to marry the two by using an LLM-based pipeline to extract scripts from videos, and then employ LLMs to imitate and create new scripts, capturing complex, time-series human behaviors and interactions with environments. By leveraging this, we utilize a dual-aware policy that achieves both language comprehension and scene understanding to guide character motions within contextual and spatial constraints. To facilitate training and evaluation, we contribute a comprehensive planning dataset containing diverse motion sequences extracted from real-world videos and expand them with large language models. We also collect and re-annotate motion clips from existing kinematic datasets to enable our policy learn diverse skills. Extensive experiments demonstrate the effectiveness of our framework in versatile task execution and its generalization ability to various scenarios, showing remarkably enhanced performance compared with existing methods. Our code and data will be publicly available soon.

Go to Zero: Towards Zero-shot Motion Generation with Million-scale Data
Ke Fan, Shulin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, Jingbo Wang
ICCV 2025 (Highlight).
Ke Fan, Shulin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, Jingbo Wang
ICCV 2025 (Highlight).
- project page
- paper
- code
-
abstract
Generating diverse and natural human motion sequences based on textual descriptions constitutes a fundamental and challenging research area within the domains of computer vision, graphics, and robotics. Despite significant advancements in this field, current methodologies often face challenges regarding zero-shot generalization capabilities, largely attributable to the limited size of training datasets. Moreover, the lack of a comprehensive evaluation framework impedes the advancement of this task by failing to identify directions for improvement. In this work, we aim to push text-to-motion into a new era, that is, to achieve the generalization ability of zero-shot. To this end, firstly, we develop an efficient annotation pipeline and introduce MotionMillion-the largest human motion dataset to date, featuring over 2,000 hours and 2 million high-quality motion sequences. Additionally, we propose MotionMillion-Eval, the most comprehensive benchmark for evaluating zero-shot motion generation. Leveraging a scalable architecture, we scale our model to 7B parameters and validate its performance on MotionMillion-Eval. Our results demonstrate strong generalization to out-of-domain and complex compositional motions, marking a significant step toward zero-shot human motion generation. The code is available at this https URL.

TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task
Tokenization
Liang Pan, Zeshi Yang, Zhiyang Dou, Wenjia Wang, Buzhen Huang, Bo Dai, Taku Komura, Jingbo Wang.
CVPR 2025 (Oral). 3.3% of accepted papers.
Liang Pan, Zeshi Yang, Zhiyang Dou, Wenjia Wang, Buzhen Huang, Bo Dai, Taku Komura, Jingbo Wang.
CVPR 2025 (Oral). 3.3% of accepted papers.
- project page
- paper
- code
-
abstract
The synthesis of realistic and physically plausible human-scene interaction animations presents a critical and complex challenge in computer vision and embodied AI. Recent advances primarily focus on developing specialized character controllers for individual interaction tasks, such as contacting and carrying, often overlooking the need to establish a unified policy for versatile skills. This limitation hinders the ability to generate high-quality motions across a variety of challenging human-scene interaction tasks that require the integration of multiple skills, e.g., walking to a chair and sitting down while carrying a box. To address this issue, we present TokenHSI, a unified controller designed to synthesize various types of human-scene interaction animations. The key innovation of our framework is the use of tokenized proprioception for the simulated character, combined with various task observations, complemented by a masking mechanism that enables the selection of tasks on demand. In addition, our unified policy network is equipped with flexible input size capabilities, enabling efficient adaptation of learned foundational skills to new environments and tasks. By introducing additional input tokens to the pre-trained policy, we can not only modify interaction targets but also integrate learned skills to address diverse challenges. Overall, our framework facilitates the generation of a wide range of character animations, significantly improving flexibility and adaptability in human-scene interactions.
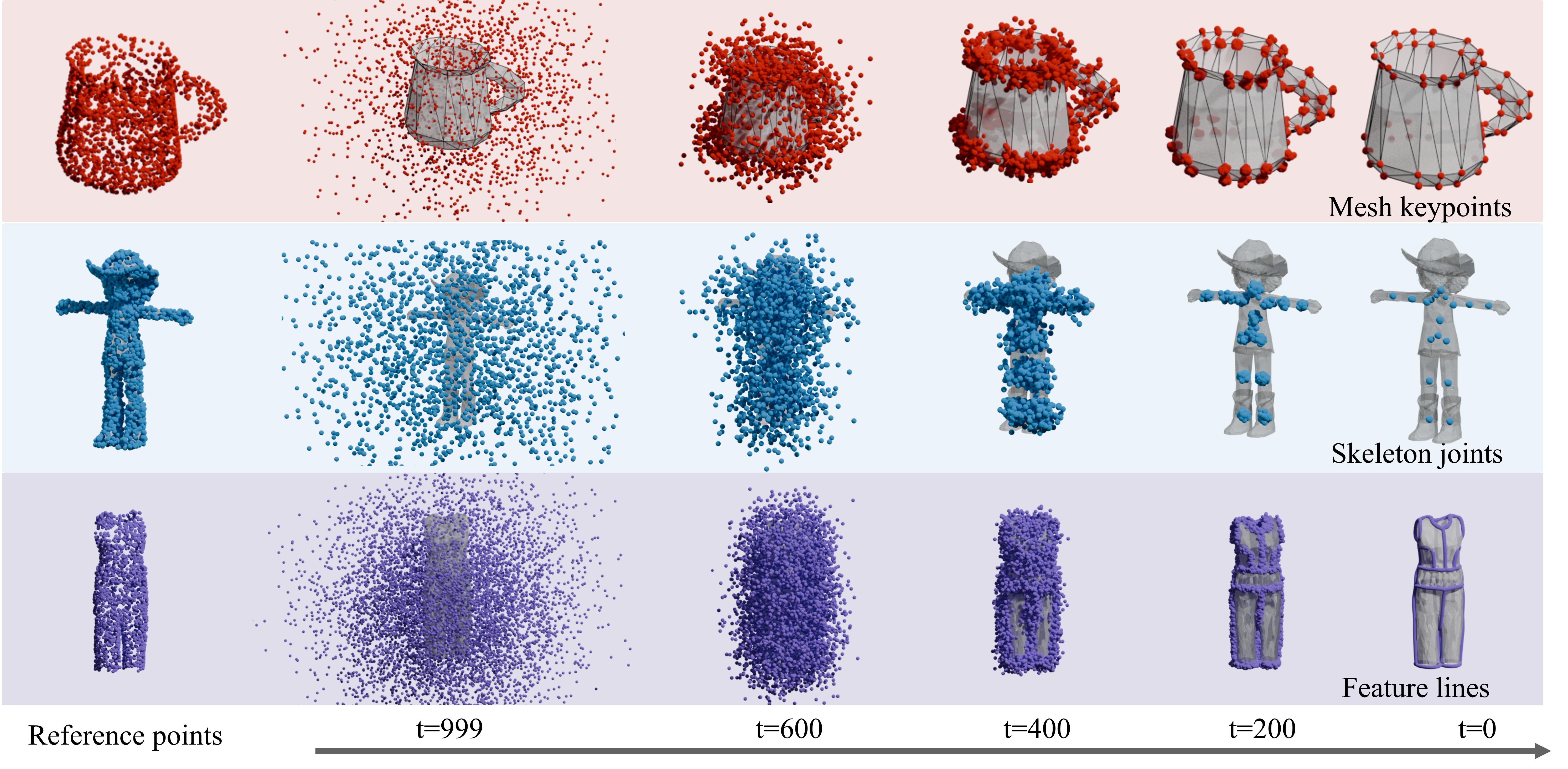
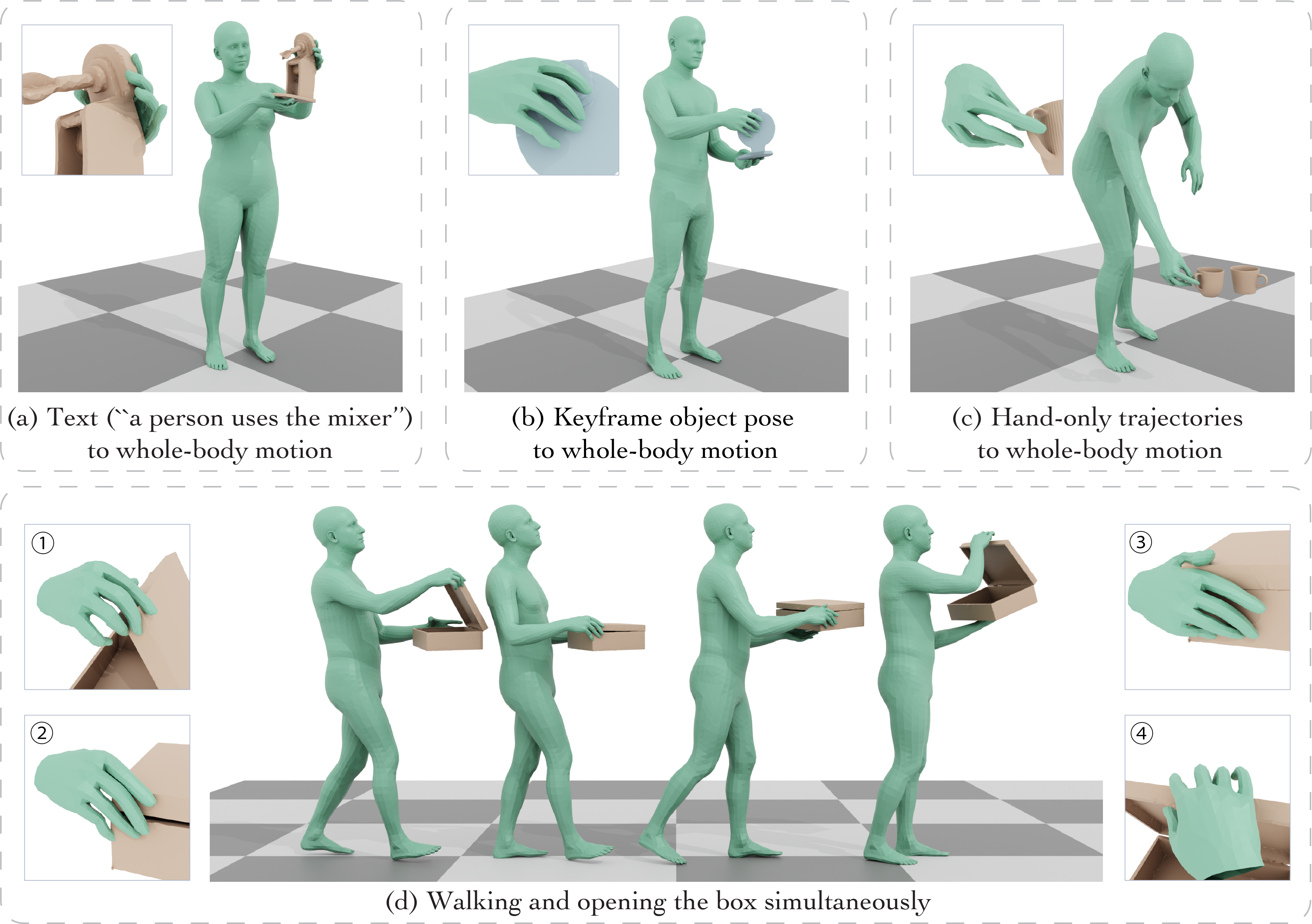
PDT: Point Distribution Transformation with Diffusion Models
Jionghao Wang, Cheng Lin, Yuan Liu, Rui Xu, Zhiyang Dou, Xiaoxiao Long, Haoxiang Guo, Taku Komura, Wenping Wang, Xin Li.
SIGGRAPH 2025.
Jionghao Wang, Cheng Lin, Yuan Liu, Rui Xu, Zhiyang Dou, Xiaoxiao Long, Haoxiang Guo, Taku Komura, Wenping Wang, Xin Li.
SIGGRAPH 2025.
- project page
- paper
- code
-
abstract
Point-based representations have consistently played a vital role in geometric data structures. Most point cloud learning and processing methods typically leverage the unordered and unconstrained nature to represent the underlying geometry of 3D shapes. However, how to extract meaningful structural information from unstructured point cloud distributions and transform them into semantically meaningful point distributions remains an under-explored problem. We present PDT, a novel framework for point distribution transformation with diffusion models. Given a set of input points, PDT learns to transform the point set from its original geometric distribution into a target distribution that is semantically meaningful. Our method utilizes diffusion models with novel architecture and learning strategy, which effectively correlates the source and the target distribution through a denoising process. Through extensive experiments, we show that our method successfully transforms input point clouds into various forms of structured outputs - ranging from surface-aligned keypoints, and inner sparse joints to continuous feature lines. The results showcase our framework's ability to capture both geometric and semantic features, offering a powerful tool for various 3D geometry processing tasks where structured point distributions are desired.

Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation
Control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, Yuan Liu.
SIGGRAPH 2025.
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, Yuan Liu.
SIGGRAPH 2025.
- project page
- paper
- code
-
abstract
Diffusion models have demonstrated impressive performance in generating high-quality videos from text prompts or images. However, precise control over the video generation process, such as camera manipulation or content editing, remains a significant challenge. Existing methods for controlled video generation are typically limited to a single control type, lacking the flexibility to handle diverse control demands. In this paper, we introduce Diffusion as Shader (DaS), a novel approach that supports multiple video control tasks within a unified architecture. Our key insight is that achieving versatile video control necessitates leveraging 3D control signals, as videos are fundamentally 2D renderings of dynamic 3D content. Unlike prior methods limited to 2D control signals, DaS leverages 3D tracking videos as control inputs, making the video diffusion process inherently 3D-aware. This innovation allows DaS to achieve a wide range of video controls by simply manipulating the 3D tracking videos. A further advantage of using 3D tracking videos is their ability to effectively link frames, significantly enhancing the temporal consistency of the generated videos. With just 3 days of fine-tuning on 8 H800 GPUs using less than 10k videos, DaS demonstrates strong control capabilities across diverse tasks, including mesh-to-video generation, camera control, motion transfer, and object manipulation.

Align3R: Aligned Monocular Depth Estimation for Dynamic Videos
Jiahao Lu*, Tianyu Huang*, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, Yuan Liu.
CVPR 2025 (Highlight). 13.5% of accepted papers.
Jiahao Lu*, Tianyu Huang*, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, Yuan Liu.
CVPR 2025 (Highlight). 13.5% of accepted papers.
- project page
- paper
- code
-
abstract
Recent developments in monocular depth estimation methods enable high-quality depth estimation of single-view images but fail to estimate consistent video depth across different frames. Recent works address this problem by applying a video diffusion model to generate video depth conditioned on the input video, which is training-expensive and can only produce scale-invariant depth values without camera poses. In this paper, we propose a novel video-depth estimation method called Align3R to estimate temporal consistent depth maps for a dynamic video. Our key idea is to utilize the recent DUSt3R model to align estimated monocular depth maps of different timesteps. First, we fine-tune the DUSt3R model with additional estimated monocular depth as inputs for the dynamic scenes. Then, we apply optimization to reconstruct both depth maps and camera poses. Extensive experiments demonstrate that Align3R estimates consistent video depth and camera poses for a monocular video with superior performance than baseline methods.

Vid2Sim: Generalizable, Video-based Reconstruction of Appearance, Geometry and Physics for
Mesh-free Simulation
Chuhao Chen, Zhiyang Dou, Chen Wang, Yiming Huang, Anjun Chen, Qiao Feng, Jiatao Gu, Lingjie Liu
CVPR 2025.
Chuhao Chen, Zhiyang Dou, Chen Wang, Yiming Huang, Anjun Chen, Qiao Feng, Jiatao Gu, Lingjie Liu
CVPR 2025.
- paper
- code
-
abstract
Faithfully reconstructing textured shapes and physical properties from videos presents an intriguing yet challenging problem. Significant efforts have been dedicated to advancing such a system identification problem in this area. Previous methods often rely on heavy optimization pipelines with a differentiable simulator and renderer to estimate physical parameters. However, these approaches frequently necessitate extensive hyperparameter tuning for each scene and involve a costly optimization process, which limits both their practicality and generalizability. In this work, we propose a novel framework, Vid2Sim, a generalizable videobased approach for recovering geometry and physical properties through a mesh-free reduced simulation based on Linear Blend Skinning (LBS), offering high computational efficiency and versatile representation capability. Specifically, Vid2Sim first reconstructs the observed configuration of the physical system from video using a feed-forward neural network trained to capture physical world knowledge. A lightweight optimization pipeline then refines the estimated appearance, geometry, and physical properties to closely align with video observations within just a few minutes. Additionally, after the reconstruction, Vid2Sim enables highquality, mesh-free simulation with high efficiency. Extensive experiments demonstrate that our method achieves superior accuracy and efficiency in reconstructing geometry and physical properties from video data.
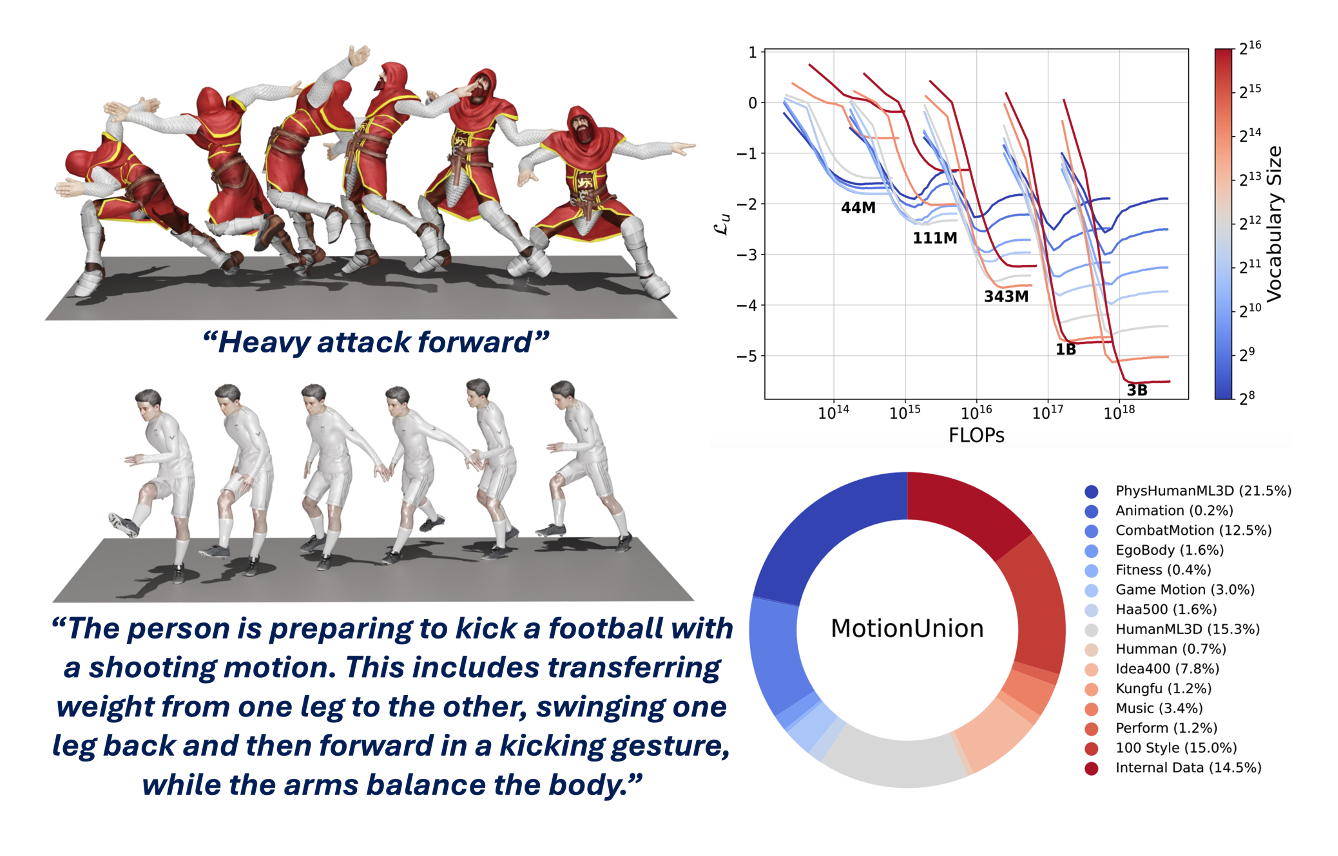
ScaMo: Exploring the Scaling Law in Autoregressive Motion Generation Model
Shunlin Lu, Jingbo Wang, Zeyu Lu, Ling-Hao Chen, Wenxun Dai, Junting Dong, Zhiyang Dou, Bo Dai, Ruimao Zhang.
CVPR 2025.
Shunlin Lu, Jingbo Wang, Zeyu Lu, Ling-Hao Chen, Wenxun Dai, Junting Dong, Zhiyang Dou, Bo Dai, Ruimao Zhang.
CVPR 2025.
- project page
- paper
- code
-
abstract
The scaling law has been validated in various domains, such as natural language processing (NLP) and massive computer vision tasks; however, its application to motion generation remains largely unexplored. In this paper, we introduce a scalable motion generation framework that includes the motion tokenizer Motion FSQ-VAE and a text-prefix autoregressive transformer. Through comprehensive experiments, we observe the scaling behavior of this system. For the first time, we confirm the existence of scaling laws within the context of motion generation. Specifically, our results demonstrate that the normalized test loss of our prefix autoregressive models adheres to a logarithmic law in relation to compute budgets. Furthermore, we also confirm the power law between Non-Vocabulary Parameters, Vocabulary Parameters, and Data Tokens with respect to compute budgets respectively. Leveraging the scaling law, we predict the optimal transformer size, vocabulary size, and data requirements for a compute budget of 1e18. The test loss of the system, when trained with the optimal model size, vocabulary size, and required data, aligns precisely with the predicted test loss, thereby validating the scaling law.
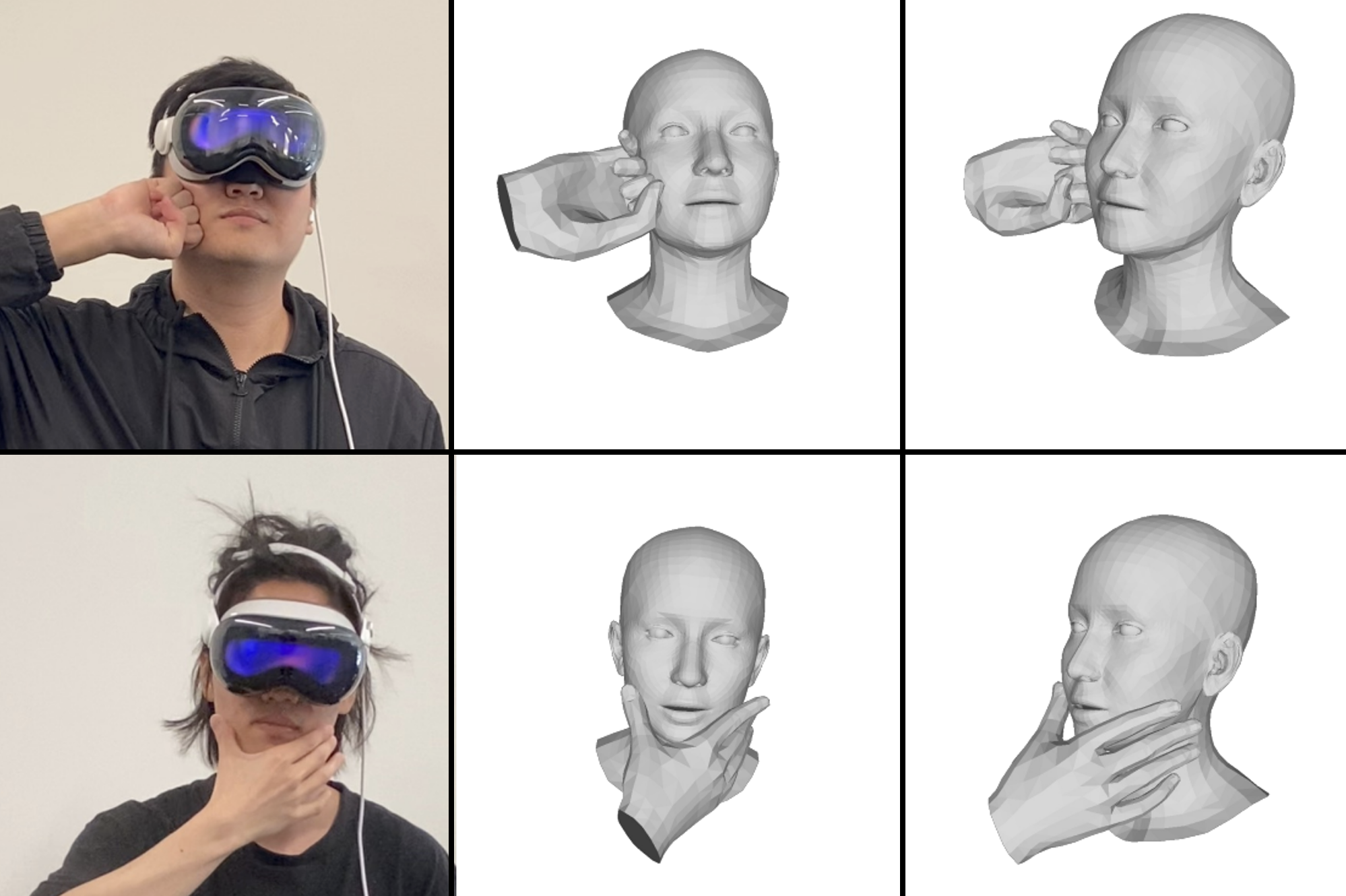
DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image
Qingxuan Wu, Zhiyang Dou†, Sirui Xu, Soshi Shimada, Chen Wang, Zhengming Yu, Yuan Liu, Cheng Lin, Zeyu Cao, Taku Komura, Vladislav Golyanik, Christian Theobalt, Wenping Wang, Lingjie Liu†.
ICLR 2025.
Qingxuan Wu, Zhiyang Dou†, Sirui Xu, Soshi Shimada, Chen Wang, Zhengming Yu, Yuan Liu, Cheng Lin, Zeyu Cao, Taku Komura, Vladislav Golyanik, Christian Theobalt, Wenping Wang, Lingjie Liu†.
ICLR 2025.
- project page
- paper
- code
-
abstract
Reconstructing 3D hand-face interactions with deformations from a single image is a challenging yet crucial task with broad applications in AR, VR, and gaming. The challenges stem from self-occlusions during single-view hand-face interactions, diverse spatial relationships between hands and face, complex deformations, and the ambiguity of the single-view setting. The first and only method for hand-face interaction recovery, Decaf, introduces a global fitting optimization guided by contact and deformation estimation networks trained on studio-collected data with 3D annotations. However, Decaf suffers from a time-consuming optimization process and limited generalization capability due to its reliance on 3D annotations of hand-face interaction data. To address these issues, we present DICE, the first end-to-end method for Deformation-aware hand-face Interaction reCovEry from a single image. DICE estimates the poses of hands and faces, contacts, and deformations simultaneously using a Transformer-based architecture. It features disentangling the regression of local deformation fields and global mesh vertex locations into two network branches, enhancing deformation and contact estimation for precise and robust hand-face mesh recovery. To improve generalizability, we propose a weakly-supervised training approach that augments the training set using in-the-wild images without 3D ground-truth annotations, employing the depths of 2D keypoints estimated by off-the-shelf models and adversarial priors of poses for supervision. Our experiments demonstrate that DICE achieves state-of-the-art performance on a standard benchmark and in-the-wild data in terms of accuracy and physical plausibility. Additionally, our method operates at an interactive rate (20 fps) on an Nvidia 4090 GPU, whereas Decaf requires more than 15 seconds for a single image. Our code will be publicly available upon publication.
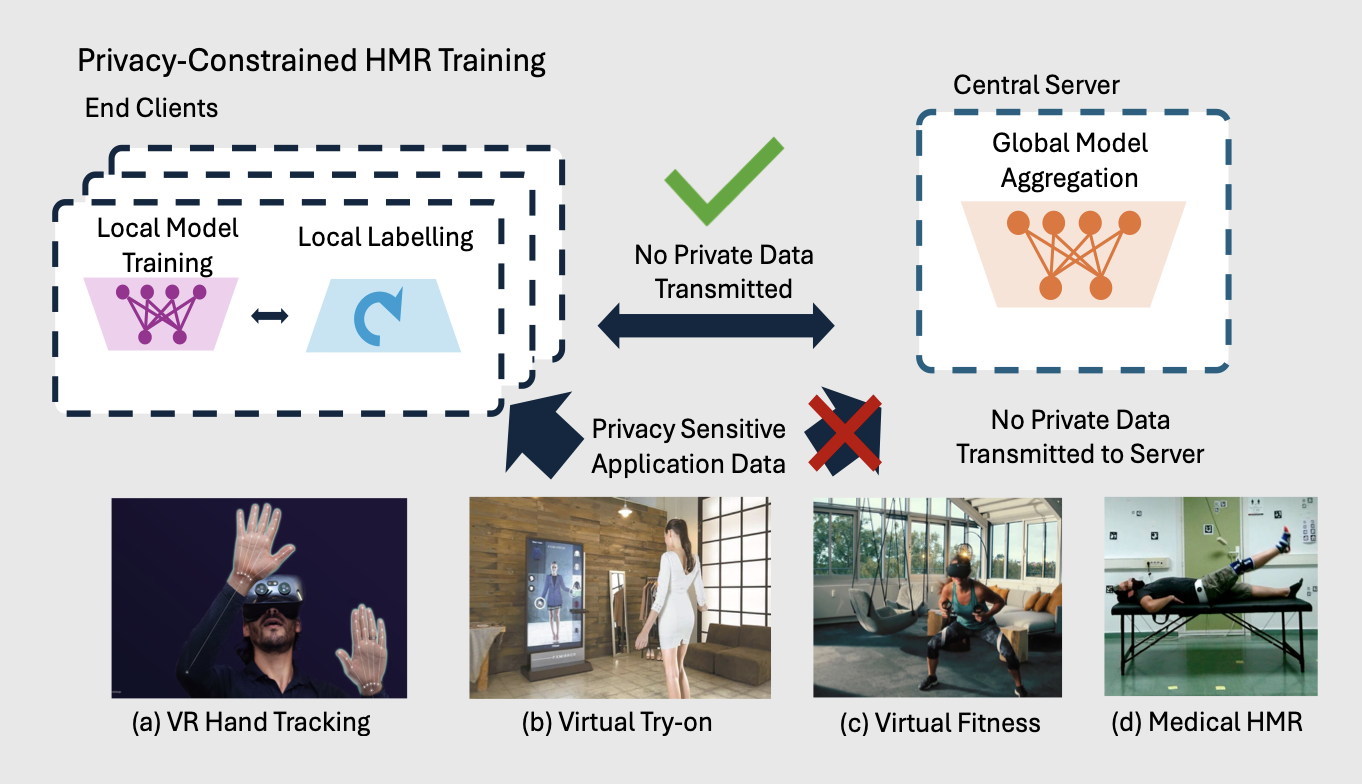
PCHMR: Empowering and Benchmarking Human Mesh Recovery in Privacy-Constrained Real-World Settings
Zeyu Cao*, Qingxuan Wu*, Zhiyang Dou†, Rui Xu, Yuan Liu, Javier Fernandez-Marques, Nicholas D. Lane, Taku Komura, Wenping Wang†.
2025.
Zeyu Cao*, Qingxuan Wu*, Zhiyang Dou†, Rui Xu, Yuan Liu, Javier Fernandez-Marques, Nicholas D. Lane, Taku Komura, Wenping Wang†.
2025.
- project page
-
abstract
Fine-tuning directly on user-side data is an effective way to improve the performance of widely adopted data-driven human mesh recovery (HMR) models. However, existing HMR methods often assume that user-side images can be aggregated to a central training server, which creates a privacy risk for sensitive human data. PCHMR studies how HMR can be evaluated and improved when raw images remain local. We benchmark state-of-the-art HMR models under federated and secure-aggregation variants, covering client scale, heterogeneous data distributions, and user-side personalization. We also introduce DePoser, a depth-aware local annotation and fine-tuning pipeline that uses foundation-model pose and depth priors to support local adaptation. The benchmark clarifies how representative HMR backbones behave when centralized data access is removed, and provides a foundation for future privacy-constrained HMR deployment.

WonderHuman: Hallucinating Unseen Parts in Dynamic 3D Human Reconstruction
Zilong Wang, Zhiyang Dou†, Yuan Liu, Cheng Lin, Xiao Dong, Yunhui Guo, Chenxu Zhang, Xin Li, Wenping Wang, Xiaohu Guo†.
IEEE Transactions on Visualization and Computer Graphics 2025.
Zilong Wang, Zhiyang Dou†, Yuan Liu, Cheng Lin, Xiao Dong, Yunhui Guo, Chenxu Zhang, Xin Li, Wenping Wang, Xiaohu Guo†.
IEEE Transactions on Visualization and Computer Graphics 2025.
- project page
- paper
- code
-
abstract
In this paper, we present WonderHuman to reconstruct dynamic human avatars from a monocular video for high-fidelity novel view synthesis. Previous dynamic human avatar reconstruction methods typically require the input video to have full coverage of the observed human body. However, in daily practice, one typically has access to limited viewpoints, such as monocular front-view videos, making it a cumbersome task for previous methods to reconstruct the unseen parts of the human avatar. To tackle the issue, we present WonderHuman, which leverages 2D generative diffusion model priors to achieve high-quality, photorealistic reconstructions of dynamic human avatars from monocular videos, including accurate rendering of unseen body parts. Our approach introduces a Dual-Space Optimization technique, applying Score Distillation Sampling (SDS) in both canonical and observation spaces to ensure visual consistency and enhance realism in dynamic human reconstruction. Additionally, we present a View Selection strategy and Pose Feature Injection to enforce the consistency between SDS predictions and observed data, ensuring pose-dependent effects and higher fidelity in the reconstructed avatar. In the experiments, our method achieves SOTA performance in producing photorealistic renderings from the given monocular video, particularly for those challenging unseen parts.

Genesis: A Generative and Universal Physics Engine for Robotics and Beyond
Zhou Xian* , Yiling Qiao*, Zhenjia Xu*, Tsun-Hsuan Wang*, Zhehuan Chen*, Juntian Zheng*, Ziyan Xiong*, Yian Wang*, Mingrui Zhang*, Pingchuan Ma*, Yufei Wang*, Zhiyang Dou*, etc.
Zhou Xian* , Yiling Qiao*, Zhenjia Xu*, Tsun-Hsuan Wang*, Zhehuan Chen*, Juntian Zheng*, Ziyan Xiong*, Yian Wang*, Mingrui Zhang*, Pingchuan Ma*, Yufei Wang*, Zhiyang Dou*, etc.
Dynamic Realms: 4D Content Analysis, Recovery and Generation with Geometric, Topological and
Physical Priors
Zhiyang Dou.
Doctoral Consortium: ECCV 2024 and Eurographics 2025.
🗺️👆Click the figure for an overview.
Zhiyang Dou.
Doctoral Consortium: ECCV 2024 and Eurographics 2025.
🗺️👆Click the figure for an overview.

CBIL: Collective Behavior Imitation Learning for Fish from Real Videos
Yifan Wu*, Zhiyang Dou* Yuko Ishiwaka, Shun Ogawa, Yuke Lou, Wenping Wang, Lingjie Liu, Taku Komura.
ACM Transactions on Graphics (SIGGRAPH Asia 2024).
Collective Behavior Imitation Learning for Fish from Real Videos, JP7786689.
Yifan Wu*, Zhiyang Dou* Yuko Ishiwaka, Shun Ogawa, Yuke Lou, Wenping Wang, Lingjie Liu, Taku Komura.
ACM Transactions on Graphics (SIGGRAPH Asia 2024).
Collective Behavior Imitation Learning for Fish from Real Videos, JP7786689.
- project page
- paper
-
abstract
Reproducing realistic collective behaviors presents a captivating yet formidable challenge. Traditional rule-based methods rely on hand-crafted principles, limiting motion diversity and realism in generated collective behaviors. Recent imitation learning methods learn from data but often require ground truth motion trajectories and struggle with authenticity, especially in high-density groups with erratic movements. In this paper, we present a scalable approach, Collective Behavior Imitation Learning (CBIL), for learning fish schooling behavior directly from videos, without relying on captured motion trajectories. Our method first leverages Video Representation Learning, where a Masked Video AutoEncoder (MVAE) extracts implicit states from video inputs in a self-supervised manner. The MVAE effectively maps 2D observations to implicit states that are compact and expressive for following the imitation learning stage. Then, we propose a novel adversarial imitation learning method to effectively capture complex movements of the schools of fish, allowing for efficient imitation of the distribution for motion patterns measured in the latent space. It also incorporates bio-inspired rewards alongside priors to regularize and stabilize training. Once trained, CBIL can be used for various animation tasks with the learned collective motion priors. We further show its effectiveness across different species. Finally, we demonstrate the application of our system in detecting abnormal fish behavior from in-the-wild videos.
ProTracker: Probabilistic Integration for Robust and Accurate Point Tracking
Tingyang Zhang, Chen Wang, Zhiyang Dou, Qingzhe Gao, Jiahui Lei, Baoquan Chen, Lingjie Liu.
arXiv 2025.
Tingyang Zhang, Chen Wang, Zhiyang Dou, Qingzhe Gao, Jiahui Lei, Baoquan Chen, Lingjie Liu.
arXiv 2025.
- project page
- paper
- code
-
abstract
In this paper, we propose ProTracker, a novel framework for robust and accurate long-term dense tracking of arbitrary points in videos. The key idea of our method is incorporating probabilistic integration to refine multiple predictions from both optical flow and semantic features for robust short-term and long-term tracking. Specifically, we integrate optical flow estimations in a probabilistic manner, producing smooth and accurate trajectories by maximizing the likelihood of each prediction. To effectively re-localize challenging points that disappear and reappear due to occlusion, we further incorporate long-term feature correspondence into our flow predictions for continuous trajectory generation. Extensive experiments show that ProTracker achieves the state-of-the-art performance among unsupervised and self-supervised approaches, and even outperforms supervised methods on several benchmarks. Our code and model will be publicly available upon publication.

MotionWavelet: Human Motion Prediction via Wavelet Manifold Learning
Yuming Feng*, Zhiyang Dou*†, Ling-Hao Chen, Yuan Liu, Tianyu Li, Jingbo Wang, Zeyu Cao, Wenping Wang, Taku Komura, Lingjie Liu†.
arXiv 2024.
Yuming Feng*, Zhiyang Dou*†, Ling-Hao Chen, Yuan Liu, Tianyu Li, Jingbo Wang, Zeyu Cao, Wenping Wang, Taku Komura, Lingjie Liu†.
arXiv 2024.
- project page
- paper
-
abstract
Modeling temporal characteristics and the non-stationary dynamics of body movement plays a significant role in predicting human future motions. However, it is challenging to capture these features due to the subtle transitions involved in the complex human motions. This paper introduces MotionWavelet, a human motion prediction framework that utilizes Wavelet Transformation and studies human motion patterns in the spatial-frequency domain. In MotionWavelet, a Wavelet Diffusion Model (WDM) learns a Wavelet Manifold by applying Wavelet Transformation on the motion data therefore encoding the intricate spatial and temporal motion patterns. Once the Wavelet Manifold is built, WDM trains a diffusion model to generate human motions from Wavelet latent vectors. In addition to the WDM, MotionWavelet also presents a Wavelet Space Shaping Guidance mechanism to refine the denoising process to improve conformity with the manifold structure. WDM also develops Temporal Attention-Based Guidance to enhance prediction accuracy. Extensive experiments validate the effectiveness of MotionWavelet, demonstrating improved prediction accuracy and enhanced generalization across various benchmarks. Our code and models will be released upon acceptance.

DMVTokenFlow: High-quality 4D Content Generation using Multiview Token Flow
Hanzhuo Huang, Yuan Liu, Ge Zheng, Jiepeng Wang, Zhiyang Dou, Sibei Yang.
ICLR 2025.
Hanzhuo Huang, Yuan Liu, Ge Zheng, Jiepeng Wang, Zhiyang Dou, Sibei Yang.
ICLR 2025.
- paper
-
abstract
=In this paper, we present MVTokenFlow for high-quality 4D content creation from monocular videos. Recent advancements in generative models such as video diffusion models and multiview diffusion models enable us to create videos or 3D models. However, extending these generative models for dynamic 4D content creation is still a challenging task that requires the generated content to be consistent spatially and temporally. To address this challenge, MVTokenFlow utilizes the multiview diffusion model to generate multiview images on different timesteps, which attains spatial consistency across different viewpoints and allows us to reconstruct a reasonable coarse 4D field. Then, MVTokenFlow further regenerates all the multiview images using the rendered 2D flows as guidance. The 2D flows effectively associate pixels from different timesteps and improve the temporal consistency by reusing tokens in the regeneration process. Finally, the regenerated images are spatiotemporally consistent and utilized to refine the coarse 4D field to get a high-quality 4D field. Experiments demonstrate the effectiveness of our design and show significantly improved quality than baseline methods.
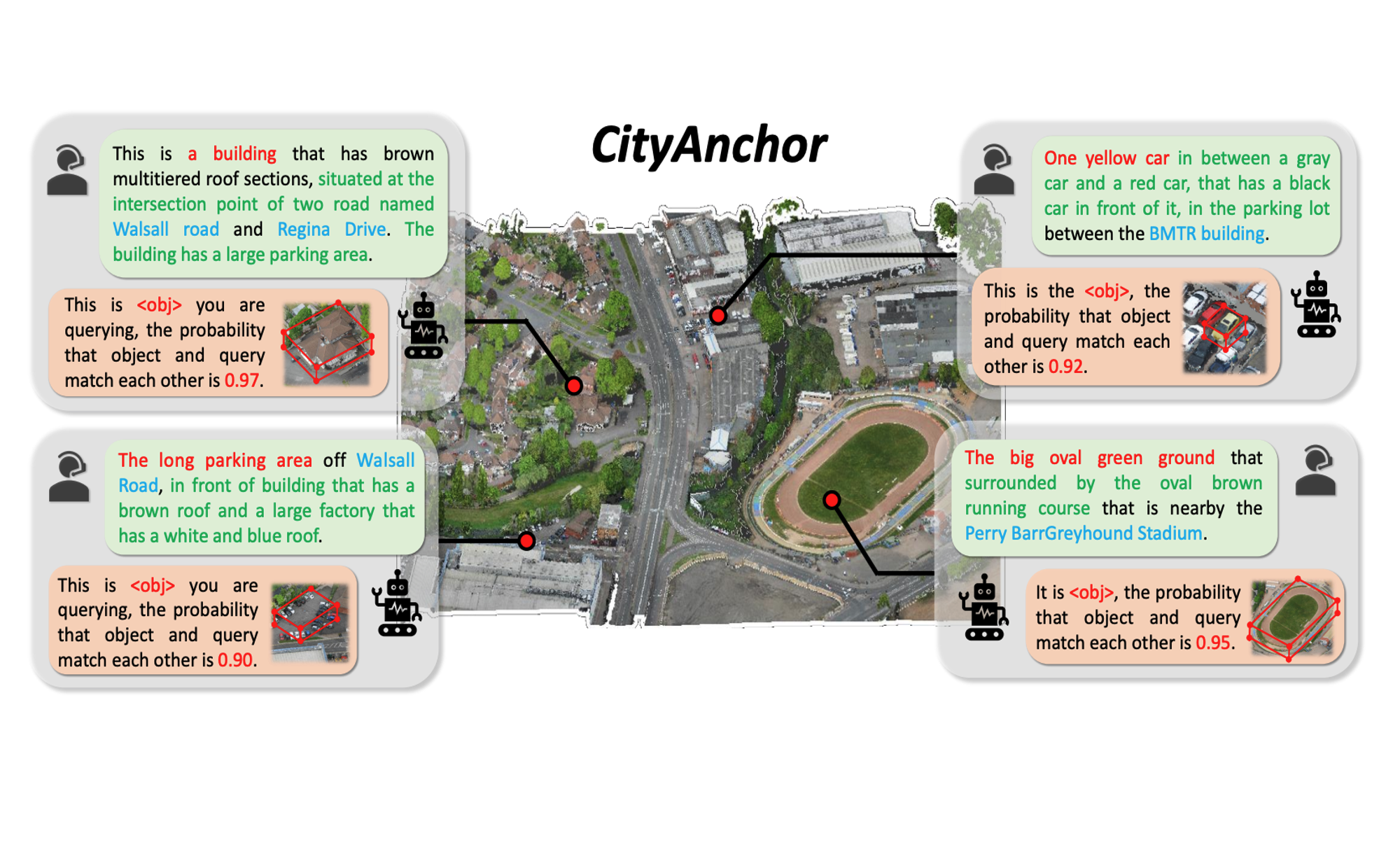
CityAnchor: City-scale 3D Visual Grounding with Multi-modality LLMs
Jinpeng Li, Haiping Wang, Jiabin chen, Yuan Liu, Zhiyang Dou, Yuexin Ma, Sibei Yang, Yuan Li, Wenping Wang, Zhen Dong, Bisheng Yang.
ICLR 2025.
Jinpeng Li, Haiping Wang, Jiabin chen, Yuan Liu, Zhiyang Dou, Yuexin Ma, Sibei Yang, Yuan Li, Wenping Wang, Zhen Dong, Bisheng Yang.
ICLR 2025.
- paper
-
abstract
In this paper, we present a 3D visual grounding method called CityAnchor for localizing an urban object in a city-scale point cloud. Recent developments in multiview reconstruction enable us to reconstruct city-scale point clouds but how to conduct visual grounding on such a large-scale urban point cloud remains an open problem. Previous 3D visual grounding system mainly concentrates on localizing an object in an image or a small-scale point cloud, which is not accurate and efficient enough to scale up to a city-scale point cloud. We address this problem with a multi-modality LLM which consists of two stages, a coarse localization and a fine-grained matching. Given the text descriptions, the coarse localization stage locates possible regions on a projected 2D map of the point cloud while the fine-grained matching stage accurately determines the most matched object in these possible regions. We conduct experiments on the CityRefer dataset and a new synthetic dataset annotated by us, both of which demonstrate our method can produce accurate 3D visual grounding on a city-scale 3D point cloud.
AutoPSV: Automated Process-Supervised Verifier
Jianqiao Lu, Zhiyang Dou, Hongru Wang, Zeyu Cao, Jianbo Dai, Yingjia Wan, Yinya Huang, Zhijiang Guo.
NeurIPS 2024.
Jianqiao Lu, Zhiyang Dou, Hongru Wang, Zeyu Cao, Jianbo Dai, Yingjia Wan, Yinya Huang, Zhijiang Guo.
NeurIPS 2024.
- paper
- code
-
abstract
In this work, we propose a novel method named \textbf{Auto}mated Process Labeling via \textbf{C}onfidence \textbf{V}ariation (\textbf{\textsc{AutoCV}}) to enhance the reasoning capabilities of large language models (LLMs) by automatically annotating the reasoning steps. Our approach begins by training a verification model on the correctness of final answers, enabling it to generate automatic process annotations. This verification model assigns a confidence score to each reasoning step, indicating the probability of arriving at the correct final answer from that point onward. We detect relative changes in the verification's confidence scores across reasoning steps to automatically annotate the reasoning process. This alleviates the need for numerous manual annotations or the high computational costs associated with model-induced annotation approaches. We experimentally validate that the confidence variations learned by the verification model trained on the final answer correctness can effectively identify errors in the reasoning steps. Subsequently, we demonstrate that the process annotations generated by \textsc{AutoCV} can improve the accuracy of the verification model in selecting the correct answer from multiple outputs generated by LLMs. Notably, we achieve substantial improvements across five datasets in mathematics and commonsense reasoning. The source code of \textsc{AutoCV} is available at \url{this https URL}.

Surf-D: High-Quality Surface Generation for Arbitrary Topologies using Diffusion
Models
Zhengming Yu*, Zhiyang Dou*, Xiaoxiao Long, Cheng Lin, Zekun Li, Yuan Liu, Norman Müller, Taku Komura, Marc Habermann, Christian Theobalt, Xin Li, Wenping Wang.
ECCV 2024.
Zhengming Yu*, Zhiyang Dou*, Xiaoxiao Long, Cheng Lin, Zekun Li, Yuan Liu, Norman Müller, Taku Komura, Marc Habermann, Christian Theobalt, Xin Li, Wenping Wang.
ECCV 2024.
- project page
- paper
- code
-
abstract
In this paper, we present Surf-D, a novel method for generating high-quality 3D shapes as Surface with arbitrary topologies using Diffusion models. Specifically, we adopt Unsigned Distance Field (UDF) as the surface representation, as it excels in handling arbitrary topologies, enabling the generation of complex shapes. While the prior methods explored shape generation with different representations, they suffer from limited topologies and geometry details. Moreover, it's non-trivial to directly extend prior diffusion models to UDF because they lack spatial continuity due to the discrete volume structure. However, UDF requires accurate gradients for mesh extraction and learning. To tackle the issues, we first leverage a point-based auto-encoder to learn a compact latent space, which supports gradient querying for any input point through differentiation to effectively capture intricate geometry at a high resolution. Since the learning difficulty for various shapes can differ, a curriculum learning strategy is employed to efficiently embed various surfaces, enhancing the whole embedding process. With pretrained shape latent space, we employ a latent diffusion model to acquire the distribution of various shapes. Our approach demonstrates superior performance in shape generation across multiple modalities and conducts extensive experiments in unconditional generation, category conditional generation, 3D reconstruction from images, and text-to-shape tasks. Our code will be publicly available upon paper publication.

EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Human Motion
Generation
Wenyang Zhou, Zhiyang Dou†, Zeyu Cao, Zhouyingcheng Liao, Jingbo Wang, Wenjia Wang, Yuan Liu, Taku Komura, Wenping Wang, Lingjie Liu.
ECCV 2024.
† Project Lead.
Wenyang Zhou, Zhiyang Dou†, Zeyu Cao, Zhouyingcheng Liao, Jingbo Wang, Wenjia Wang, Yuan Liu, Taku Komura, Wenping Wang, Lingjie Liu.
ECCV 2024.
† Project Lead.
- project page
- paper
- video
- code
-
abstract
We introduce Efficient Motion Diffusion Model (EMDM) for fast and high-quality human motion generation. Although previous motion diffusion models have shown impressive results, they struggle to achieve fast generation while maintaining high-quality human motions. Motion latent diffusion has been proposed for efficient motion generation. However, effectively learning a latent space can be non-trivial in such a two-stage manner. Meanwhile, accelerating motion sampling by increasing the step size, e.g., DDIM, typically leads to a decline in motion quality due to the inapproximation of complex data distributions when naively increasing the step size. In this paper, we propose EMDM that allows for much fewer sample steps for fast motion generation by modeling the complex denoising distribution during multiple sampling steps. Specifically, we develop a Conditional Denoising Diffusion GAN to capture multimodal data distributions conditioned on both control signals, i.e., textual description and denoising time step. By modeling the complex data distribution, a larger sampling step size and fewer steps are achieved during motion synthesis, significantly accelerating the generation process. To effectively capture the human dynamics and reduce undesired artifacts, we employ motion geometric loss during network training, which improves the motion quality and training efficiency. As a result, EMDM achieves a remarkable speed-up at the generation stage while maintaining high-quality motion generation in terms of fidelity and diversity.
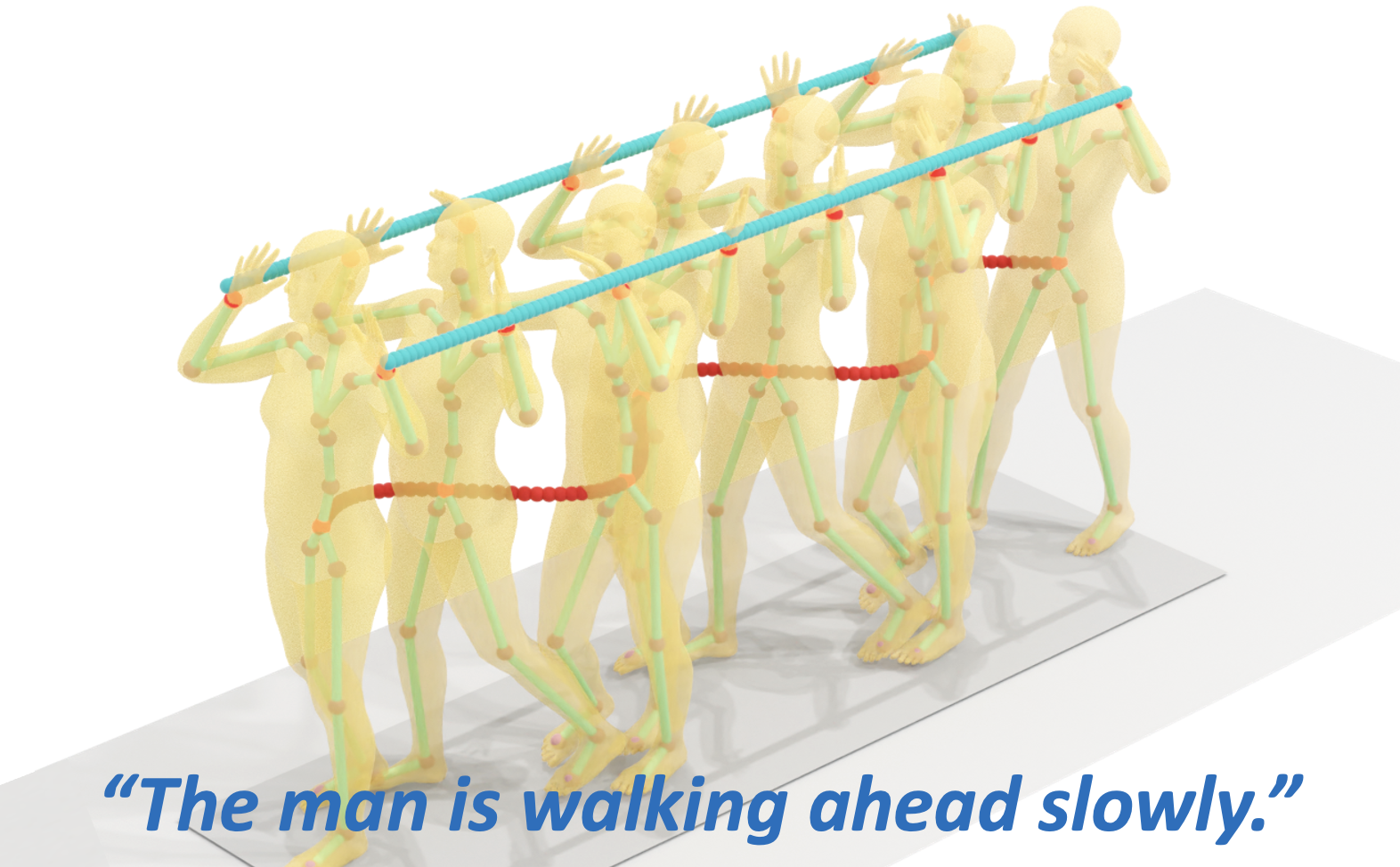
TLControl: Trajectory and Language Control for Human Motion Synthesis
Weilin Wan, Zhiyang Dou, Taku Komura, Wenping Wang, Dinesh Jayaraman, Lingjie Liu.
ECCV 2024.
Weilin Wan, Zhiyang Dou, Taku Komura, Wenping Wang, Dinesh Jayaraman, Lingjie Liu.
ECCV 2024.
- project page
- paper
- video
- code
-
abstract
Controllable human motion synthesis is essential for applications in AR/VR, gaming, movies, and embodied AI. Existing methods often focus solely on either language or full trajectory control, lacking precision in synthesizing motions aligned with user-specified trajectories, especially for multi-joint control. To address these issues, we present TLControl, a new method for realistic human motion synthesis, incorporating both low-level trajectory and high-level language semantics controls. Specifically, we first train a VQ-VAE to learn a compact latent motion space organized by body parts. We then propose a Masked Trajectories Transformer to make coarse initial predictions of full trajectories of joints based on the learned latent motion space, with user-specified partial trajectories and text descriptions as conditioning. Finally, we introduce an efficient test-time optimization to refine these coarse predictions for accurate trajectory control. Experiments demonstrate that TLControl outperforms the state-of-the-art in trajectory accuracy and time efficiency, making it practical for interactive and high-quality animation generation.

Disentangled Clothed Avatar Generation from Text Descriptions
Jionghao Wang*, Yuan Liu*, Zhiyang Dou, Zhengming Yu, Yongqing Liang, Xin Li, Wenping Wang, Rong Xie, Li Song.
ECCV 2024.
Jionghao Wang*, Yuan Liu*, Zhiyang Dou, Zhengming Yu, Yongqing Liang, Xin Li, Wenping Wang, Rong Xie, Li Song.
ECCV 2024.
- project page
- paper
- code
-
abstract
In this paper, we introduced a novel text-to-avatar generation method that separately generates the human body and the clothes and allows high-quality animation on the generated avatar. While recent advancements in text-to-avatar generation have yielded diverse human avatars from text prompts, these methods typically combine all elements—clothes, hair, and body—into a single 3D representation. Such an entangled approach poses challenges for downstream tasks like editing or animation. To overcome these limitations, we propose a novel disentangled 3D avatar representation named Sequentially Offset-SMPL (SO-SMPL), building upon the SMPL model. SO-SMPL represents the human body and clothes with two separate meshes, but associates them with offsets to ensure the physical alignment between the body and the clothes. Then, we design an Score Distillation Sampling(SDS)-based distillation framework to generate the proposed SO-SMPL representation from text prompts. In comparison with existing text-to-avatar methods, our approach not only achieves higher exture and geometry quality and better semantic alignment with text prompts, but also significantly improves the visual quality of character animation, virtual try-on, and avatar editing.

Coverage Axis++: Efficient Skeletal Points Selection for 3D Shape Skeletonization
Zimeng Wang*, Zhiyang Dou*, Rui Xu, Cheng Lin, Yuan Liu, Xiaoxiao Long, Shiqing Xin, Taku Komura, Xiaoming Yuan, Wenping Wang.
ACM SIGGRAPH/Eurographics Symposium on Geometry Processing 2024. Top Viewed Article in Computer Graphics Forum 2024. A follow-up of Coverage Axis.
Zimeng Wang*, Zhiyang Dou*, Rui Xu, Cheng Lin, Yuan Liu, Xiaoxiao Long, Shiqing Xin, Taku Komura, Xiaoming Yuan, Wenping Wang.
ACM SIGGRAPH/Eurographics Symposium on Geometry Processing 2024. Top Viewed Article in Computer Graphics Forum 2024. A follow-up of Coverage Axis.
- project page
- paper
- code
-
abstract
We introduce Coverage Axis++, a novel and efficient approach to 3D shape skeletonization. The current state-of-the-art approaches for this task often rely on the watertightness of the input or suffer from substantial computational costs, thereby limiting their practicality. To address this challenge, Coverage Axis++ proposes a heuristic algorithm to select skeletal points, offering a high-accuracy approximation of the Medial Axis Transform (MAT) while significantly mitigating computational intensity for various shape representations. We introduce a simple yet effective strategy that considers both shape coverage and uniformity to derive skeletal points. The selection procedure enforces consistency with the shape structure while favoring the dominant medial balls, which thus introduces a compact underlying shape representation in terms of MAT. As a result, Coverage Axis++ allows for skeletonization for various shape representations (e.g., water-tight meshes, triangle soups, point clouds), specification of the number of skeletal points, few hyperparameters, and highly efficient computation with improved reconstruction accuracy. Extensive experiments across a wide range of 3D shapes validate the efficiency and effectiveness of Coverage Axis++. The code will be publicly available once the paper is published.
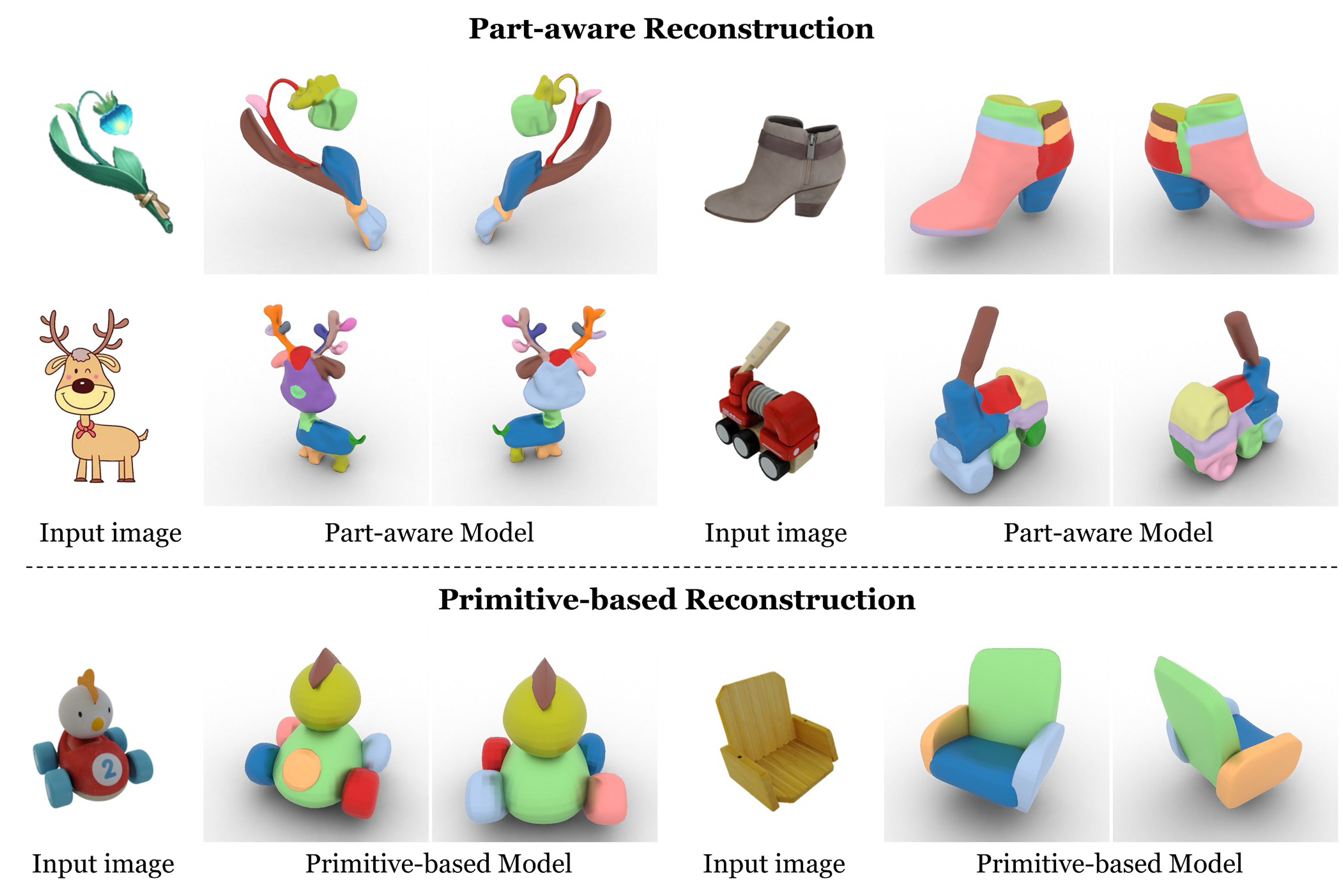
Part123: Part-aware 3D Reconstruction from a Single-view Image
Anran Liu*, Cheng Lin* , Yuan Liu, Xiaoxiao Long, Zhiyang Dou, Haoxiang Guo, Ping Luo, Wenping Wang.
SIGGRAPH 2024.
Anran Liu*, Cheng Lin* , Yuan Liu, Xiaoxiao Long, Zhiyang Dou, Haoxiang Guo, Ping Luo, Wenping Wang.
SIGGRAPH 2024.
- project page
- paper
- code (cs)
-
abstract
Recently, the emergence of diffusion models has opened up new opportunities for single-view reconstruction. However, all the existing methods represent the target object as a closed mesh devoid of any structural information, thus neglecting the part-based structure, which is crucial for many downstream applications, of the reconstructed shape. Moreover, the generated meshes usually suffer from large noises, unsmooth surfaces, and blurry textures, making it challenging to obtain satisfactory part segments using 3D segmentation techniques. In this paper, we present Part123, a novel framework for part-aware 3D reconstruction from a single-view image. We first use diffusion models to generate multiview-consistent images from a given image, and then leverage Segment Anything Model (SAM), which demonstrates powerful generalization ability on arbitrary objects, to generate multiview segmentation masks. To effectively incorporate 2D part-based information into 3D reconstruction and handle inconsistency, we introduce contrastive learning into a neural rendering framework to learn a part-aware feature space based on the multiview segmentation masks. A clustering-based algorithm is also developed to automatically derive 3D part segmentation results from the reconstructed models. Experiments show that our method can generate 3D models with high-quality segmented parts on various objects. Compared to existing unstructured reconstruction methods, the part-aware 3D models from our method benefit some important applications, including feature-preserving reconstruction, primitive fitting, and 3D shape editing.

Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Xiaoxiao Long*, Yuanchen Guo*, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, Wenping Wang.
CVPR 2024 (Highlight). 11.9% of accepted papers.
Xiaoxiao Long*, Yuanchen Guo*, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, Wenping Wang.
CVPR 2024 (Highlight). 11.9% of accepted papers.
- project page
- paper
- code
- Hugging Face Demo
-
abstract
In this work, we introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images.Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details. To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and reasonably good efficiency compared to prior works.

C·ASE: Learning Conditional Adversarial Skill Embeddings for Physics-based
Characters
Zhiyang Dou, Xuelin Chen, Qingnan Fan, Taku Komura, Wenping Wang.
SIGGRAPH Asia 2023.
Zhiyang Dou, Xuelin Chen, Qingnan Fan, Taku Komura, Wenping Wang.
SIGGRAPH Asia 2023.
- project page
- paper
- video
- code
-
abstract
We present C·ASE, an efficient and effective framework that learns Conditional Adversarial Skill Embeddings for physics-based characters. C·ASE enables the physically simulated character to learn a diverse repertoire of skills while providing controllability in the form of direct manipulation of the skills to be performed. This is achieved by dividing the heterogeneous skill motions into distinct subsets containing homogeneous samples for training a low-level conditional model to learn the conditional behavior distribution. The skill-conditioned imitation learning naturally offers explicit control over the character’s skills after training. The training course incorporates the focal skill sampling, skeletal residual forces, and element-wise feature masking to balance diverse skills of varying complexities, mitigate dynamics mismatch to master agile motions and capture more general behavior characteristics, respectively. Once trained, the conditional model can produce highly diverse and realistic skills, outperforming state-of-the-art models, and can be repurposed in various downstream tasks. In particular, the explicit skill control handle allows a high-level policy or a user to direct the character with desired skill specifications, which we demonstrate is advantageous for interactive character animation.

TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer
Zhiyang Dou*, Qingxuan Wu*, Cheng Lin, Zeyu Cao, Qiangqiang Wu, Weilin Wan, Taku Komura, Wenping Wang.
ICCV 2023.
Zhiyang Dou*, Qingxuan Wu*, Cheng Lin, Zeyu Cao, Qiangqiang Wu, Weilin Wan, Taku Komura, Wenping Wang.
ICCV 2023.
- project page
- paper
- code
-
abstract
In this paper, we introduce a set of effective TOken REduction (TORE) strategies for Transformer-based Human Mesh Recovery from monocular images. Current SOTA performance is achieved by Transformer-based structures. However, they suffer from high model complexity and computation cost caused by redundant tokens. We propose token reduction strategies based on two important aspects, i.e., the 3D geometry structure and 2D image feature, where we hierarchically recover the mesh geometry with priors from body structure and conduct token clustering to pass fewer but more discriminative image feature tokens to the Transformer. As a result, our method vastly reduces the number of tokens involved in high-complexity interactions in the Transformer, achieving competitive accuracy of shape recovery at a significantly reduced computational cost. We conduct extensive experiments across a wide range of benchmarks to validate the proposed method and further demonstrate the generalizability of our method on hand mesh recovery. Our code will be publicly available once the paper is published.
Globally Consistent Normal Orientation for Point Clouds by Regularizing the Winding-Number
Field
Rui Xu, Zhiyang Dou, Ningna Wang, Shiqing Xin, Shuangmin Chen, Mingyan Jiang, Xiaohu Guo, Wenping Wang, Changhe Tu.
ACM Transactions on Graphics (SIGGRAPH 2023). Best Paper Award at SIGGRAPH 2023; see more here.
Rui Xu, Zhiyang Dou, Ningna Wang, Shiqing Xin, Shuangmin Chen, Mingyan Jiang, Xiaohu Guo, Wenping Wang, Changhe Tu.
ACM Transactions on Graphics (SIGGRAPH 2023). Best Paper Award at SIGGRAPH 2023; see more here.
- project page
- paper
- video
- code
-
abstract
Estimating normals with globally consistent orientations for a raw point cloud has many downstream geometry processing applications. Despite tremendous efforts in the past decades, it remains challenging to deal with an unoriented point cloud with various imperfections, particularly in the presence of data sparsity coupled with nearby gaps or thin-walled structures. In this paper, we propose a smooth objective function to characterize the requirements of an acceptable winding-number field, which allows one to find the globally consistent normal orientations starting from a set of completely random normals. By taking the vertices of the Voronoi diagram of the point cloud as examination points, we consider the following three requirements: (1) the winding number is either 0 or 1, (2) the occurrences of 1 and the occurrences of 0 are balanced around the point cloud, and (3) the normals align with the outside Voronoi poles as much as possible. Extensive experimental results show that our method outperforms the existing approaches, especially in handling sparse and noisy point clouds, as well as shapes with complex geometry/topology.

RFEPS: Reconstructing Feature-line Equipped Polygonal Surface
Rui Xu, Zixiong Wang, Zhiyang Dou, Chen Zong, Shiqing Xin, Mingyan Jiang, Tao Ju, Changhe Tu.
ACM Transactions on Graphics (SIGGRAPH Asia 2022).
Rui Xu, Zixiong Wang, Zhiyang Dou, Chen Zong, Shiqing Xin, Mingyan Jiang, Tao Ju, Changhe Tu.
ACM Transactions on Graphics (SIGGRAPH Asia 2022).
- project page
- paper
- video
- code
-
abstract
Feature lines are important geometric cues in characterizing the structure of a CAD model. Despite great progress in both explicit reconstruction and implicit reconstruction, it remains a challenging task to reconstruct a polygonal surface equipped with feature lines, especially when the input point cloud is noisy and lacks faithful normal vectors. In this paper, we develop a multistage algorithm, named RFEPS, to address this challenge. The key steps include (1)denoising the point cloud based on the assumption of local planarity, (2)identifying the feature-line zone by optimization of discrete optimal transport, (3)augmenting the point set so that sufficiently many additional points are generated on potential geometry edges, and (4) generating a polygonal surface that interpolates the augmented point set based on restricted power diagram. We demonstrate through extensive experiments that RFEPS, benefiting from the edge-point augmentation and the feature-preserving explicit reconstruction, outperforms state-of-the-art methods in terms of the reconstruction quality, especially in terms of the ability to reconstruct missing feature lines.

Coverage Axis: Inner Point Selection for 3D Shape Skeletonization
Zhiyang Dou, Cheng Lin, Rui Xu, Lei Yang, Shiqing Xin, Taku Komura, Wenping Wang.
Computer Graphics Forum (Eurographics 2022). Top Cited Article in Computer Graphics Forum 2022–2023.
Fast-Forward Attendees Award at Eurographics 2022, 2nd Place.
Zhiyang Dou, Cheng Lin, Rui Xu, Lei Yang, Shiqing Xin, Taku Komura, Wenping Wang.
Computer Graphics Forum (Eurographics 2022). Top Cited Article in Computer Graphics Forum 2022–2023.
Fast-Forward Attendees Award at Eurographics 2022, 2nd Place.
- project page
- paper
- code
- suppl.
-
abstract
In this paper, we present a simple yet effective formulation called Coverage Axis for 3D shape skeletonization. Inspired by the set cover problem, our key idea is to cover all the surface points using as few inside medial balls as possible. This formulation inherently induces a compact and expressive approximation of the Medial Axis Transform (MAT) of a given shape. Different from previous methods that rely on local approximation error, our method allows a global consideration of the overall shape structure, leading to an efficient high-level abstraction and superior robustness to noise. Another appealing aspect of our method is its capability to handle more generalized input such as point clouds and poor-quality meshes. Extensive comparisons and evaluations demonstrate the remarkable effectiveness of our method for generating compact and expressive skeletal representation to approximate the MAT.

Respiratory Infectious Disease Transmission of Dental Healthcare Workers
Shenglan Xiao, Yingjie Luo, Fangli Zhao, Zhiyang Dou, Bing Cao, Han Yu, Nan Zhang
Journal of Hazardous Materials 2025.
Shenglan Xiao, Yingjie Luo, Fangli Zhao, Zhiyang Dou, Bing Cao, Han Yu, Nan Zhang
Journal of Hazardous Materials 2025.
- paper
-
abstract
Respiratory pathogens significantly impact public health, with transmission primarily occurring during close contact. Dental healthcare workers (HCWs) are particularly at high risk due to long-term mouth opening of patients, and frequent close proximity between HCWs and patients. This study systematically analyzed close contact patterns in 200 dental procedures in mainland China's specialized dental settings, developing a mechanistic model to quantify exposure doses and infection risks for HCWs treating patients with respiratory infections. Findings revealed that the infection risks among dentists are 5.0-fold that among assistants, underscoring the need for enhanced protective measures. Infection risks for assistants were significantly impacted by patient age, especially in cases involving patients under 14 years, while disease type influenced risks for both dentists and assistants, with higher risks in prosthodontics and orthodontics. The assessments of protective measures for HCWs showed that combining N95 respirators with face shields provided over 95 % protection, while N95 respirators alone conferred over 89 % protection, suitable for high-risk settings. Face shields with surgical masks offered over 75 % protection, providing a cost-effective alternative in resource-limited environments. These results emphasize the importance of tailoring protective strategies to specific risk factors, offering valuable guidance for infection control practices in specialist-based dental healthcare systems.

Infection Transmission-related Close Contact Behaviours in Rural China
Jiayu Qian*, Zhiyang Dou*, Zhikang Xu, Yuze Li, Zeyang Li, Yuguo Li, Ying Ji, Nan Zhang
Journal of Building Engineering 2025.
Jiayu Qian*, Zhiyang Dou*, Zhikang Xu, Yuze Li, Zeyang Li, Yuguo Li, Ying Ji, Nan Zhang
Journal of Building Engineering 2025.
- paper
-
abstract
Due to relative poverty, a low education level, and high population vulnerability, China's rural areas face challenges in preventing and controlling infectious diseases. Close contact data are essential for understanding the spread of infections, however, they are currently unavailable. This study provides the first data of close-contact behaviours in six types of indoor environment in China's rural areas, fixed red-green-blue-depth (RGBD) cameras were installed in each tested room, and captured 178 h of videos including over 22 million two-person close contact behaviors. We used computer vision technology and manual analysis to collect key parameters related to close contact, including interpersonal distance, relative facial orientation, number of people indoors, room close contact ratio, number of people per close contact and conversation time rate. Classrooms had the highest number of people per close contact (3.8) and room close contact rate (92.3 %). Restaurants had the highest conversation rate (47.9 %), face-to-face rate during close contact (21.9 %), and the shortest average interpersonal distance (0.95 m). Close-contact behaviours in rural areas differed from those in urban areas, with the greatest differences in classrooms and health clinics. Homes, restaurants, clinics and classrooms posed high infection risks, based on behavioral characteristics. This study can help to deduce potential infection risks in these environments and support for targeted epidemic prevention and control.

Transmission of Respiratory Diseases in High-metabolic Environments: A Case Study of
Gym
Haochen Zhang*, Pengcheng Zhao*, Zhiyang Dou, Boni Su, Yuguo Li, Nan Zhang
Building and Environment 2024.
Haochen Zhang*, Pengcheng Zhao*, Zhiyang Dou, Boni Su, Yuguo Li, Nan Zhang
Building and Environment 2024.
- paper
-
abstract
Outbreaks of respiratory infectious diseases have often been reported in fitness centers, likely attributed to high population density, extensive shared surfaces, and elevated metabolic equivalent (MET) levels. This study analyzed the behaviors of 30 gym attendees to establish a connection between exercise intensity and virus exposure. Close interactions among participants were tracked using self-developed wearable devices that utilized computer vision technologies, while surface-contact behaviors were recorded using video cameras. A multi-route transmission model for respiratory infectious diseases was subsequently created, integrating the observed behaviors. The Omicron variant of COVID-19 served as a case study to evaluate infection risk via various transmission routes and to assess the efficacy of interventions. The METs during physical activity were about 3.5 times higher than those recorded at rest. The average interpersonal distance during close interactions in the gym was measured at 0.82 m, with 36.7% of interactions occurring face-to-face. On average, the participants made contact with surfaces 770.3 times per hour, with 517.5 of these contacts involving public surfaces. The hourly infection rate was calculated at 18.5%, with long-range airborne transmission and close contact accounting for 70.1% and 28.5% of the cases, respectively. To mitigate transmission risk, several intervention scenarios were modeled. These included (1) 100% mask-wearing with N95 masks and occupancy reduced to 62% (25 m²/person); (2) 100% mask-wearing with surgical masks and occupancy reduced to 26% (59.6 m²/person); (3) no mask-wearing, with occupancy reduced to 18% (86.1 m²/person). All scenarios fulfilled the criteria for achieving an R below 1, indicating that under these conditions, gyms could be reopened safely.
What Influences the Close Contact Between Health Care Workers and Patients? An Observational
Study in a Hospital Dental Outpatient Department
Fangli Zhao*, Nan Zhang*, Yadi Wu, Zhiyang Dou, Bing Cao, Yingjie Luo, Yan Lu, Li Du, Shenglan Xiao.
American Journal of Infection Control 2024.
Fangli Zhao*, Nan Zhang*, Yadi Wu, Zhiyang Dou, Bing Cao, Yingjie Luo, Yan Lu, Li Du, Shenglan Xiao.
American Journal of Infection Control 2024.
- paper
-
abstract
Background: Dental outpatient departments, characterized by close proximity and unmasked patients, present a considerable risk of respiratory infections for health care workers (HCWs). However, the lack of comprehensive data on close contact (< 1.5 m) between HCWs and patients poses a significant obstacle to the development of targeted control strategies. Methods: An observation study was conducted at a hospital in Shenzhen, China, utilizing depth cameras with machine learning to capture close-contact behaviors of patients with HCWs. Additionally, questionnaires were administered to collect patient demographics. Results: The study included 200 patients, 10 dental practitioners, and 10 nurses. Patients had significantly higher close-contact rates with dental practitioners (97.5%) compared with nurses (72.8%, P < .001). The reason for the visit significantly influenced patient-practitioner (P = .018) and patient-nurse (P = .007) close-contact time, with the highest values observed in prosthodontics and orthodontics patients. Furthermore, patient age also significantly impacted the close-contact rate with nurses (P = .024), with the highest rate observed in patients below 14 years old at 85% [interquartile range: 70-93]. Conclusions:Dental outpatient departments exhibit high HCW-patient close-contact rates, influenced by visit purpose and patient age. Enhanced infection control measures are warranted, particularly for prosthodontics and orthodontics patients or those below 14 years old.
Popularization of High-Speed Railway Reduces the Infection Risk via Close Contact Route
during Journey
Nan Zhang, Xiyue Liu, Shuyi Gao, Boni Su, Zhiyang Dou†.
Sustainable Cities and Society (SCS) 2023.
Nan Zhang, Xiyue Liu, Shuyi Gao, Boni Su, Zhiyang Dou†.
Sustainable Cities and Society (SCS) 2023.
- paper
-
abstract
The risk of COVID-19 infection has increased due to the prolonged duration of travel and frequent close interactions due to popularization of railway transportations. This study utilized depth detection devices to analyze the close contact behaviors of passengers in high-speed train (HST), traditional trains (TT), waiting area in waiting room (WWR), and ticket check area in waiting room (CWR). A multi-route COVID-19 transmission model was developed to assess the risk of virus exposure in these scenarios under various non-pharmaceutical interventions. A total of 163,740 seconds of data was collected. The close contact ratios in HST, TT, WWR, and CWR was 5.8%, 64.0%, 7.7%, and 49.0%, respectively. The average interpersonal distance between passengers was 0.85 m, 0.92 m, 1.25 m, and 0.88 m, respectively. The probability of face-to-face contact was 9.5%, 70.0%, 64.2%, and 5.8% across each environment, respectively. When all passengers wore N95 respirators and surgical masks, the personal virus exposure via close contact can be reduced by 94.1% and 51.9%, respectively. The virus exposure in TT is about dozens of times of it in HST. In China, if all current railway traffic was replaced by HST, the total virus exposure of passengers can be reduced by roughly 50%.

Analysis of SARS-CoV-2 Transmission in Airports based on Real Human Close Contact
Behaviors
Xueze Yang*, Zhiyang Dou*, Yuqing Ding, Boni Su, Hua Qian, Nan Zhang.
Journal of Building Engineering (JOBE) 2023.
Xueze Yang*, Zhiyang Dou*, Yuqing Ding, Boni Su, Hua Qian, Nan Zhang.
Journal of Building Engineering (JOBE) 2023.
- paper
-
abstract
The COVID-19 pandemic has significantly impacted people's daily lives for over three years. Airports, with their dense population and frequent close contact, pose a higher risk of respiratory infectious diseases compared to many other indoor environments. However, limited availability of data on close contact behavior has resulted in a gap in indoor exposure analysis. This study conducted depth sensor measurements and video data collection across nine areas of a northern (airport A) and a southern (airport B) airports in China by 11 participants. The data, comprising more than 44 hours of close contact behaviors, including interpersonal distance, relative facial orientation, and the relative position of individuals, were analyzed using a semi-supervised machine learning method. Based on this analysis, a close contact transmission model for COVID-19 was developed, which considers the aforementioned close contact behaviors to assess the risk of exposure and the efficacy of interventions. The average close contact ratio in 9 airport’s areas is 25.4% (ranging from 6.1% to 55.0%), with passengers having the highest frequency of close contact in manual check-in areas. During close contacts, the average interpersonal distance in airports is 1.2 meters (ranging from 1.1 to 1.4 meters), being shortest in boarding areas. Face-to-face close contact is highest in charging areas, with a percentage of 46.9%. If people maintain a distance of over 1.0 meter in all areas, the total virus exposure could be reduced by 6.9% to 22.0% compared to the actual situation. Dining areas have the highest virus exposure risk for both short-range inhalation and mucosal deposition, followed by manual check-in areas. This study provides a data support for the scientific epidemic prevention and control in airports from the viewpoint of close contact behaviors.
Student close contact behavior and COVID-19 transmission in China’s classrooms
Yong Guo*, Zhiyang Dou*, Nan Zhang, Xiyue Liu, Boni Su, Yuguo Li, Yinping Zhang.
PNAS Nexus 2023.
Yong Guo*, Zhiyang Dou*, Nan Zhang, Xiyue Liu, Boni Su, Yuguo Li, Yinping Zhang.
PNAS Nexus 2023.
This research has been featured in a press release by EurekAlert!
- project page
- paper
- press release
-
abstract
Classrooms are high-risk indoor environments, so analysis of SARS-CoV-2 transmission in classrooms is important for determining optimal interventions. Due to the absence of human behavior data, it is challenging to accurately determine virus exposure in classrooms. A wearable device for close contact behavior detection was developed, and we recorded more than 250-thousand data points of close contact behaviors of students from Grades 1 through 12. Combined with a survey on students’ behaviors, we analyzed virus transmission in classrooms. Close contact rates for students were 37%±11% during classes and 48%±13% during breaks. Students in lower grades had higher close contact rates and virus transmission potential. The long-range airborne transmission route is dominant, accounting for 90%±3.6% and 75%±7.7% with and without mask wearing, respectively. During breaks, the short-range airborne route became more important, contributing 48%±3.1% in grades 1 to 9 (without wearing masks). Ventilation alone cannot always meet the demands of COVID-19 control, 30 m3/h/person is suggested as the threshold outdoor air ventilation rate in classroom. This study provides scientific support for COVID-19 prevention and control in classrooms, and our proposed human behavior detection and analysis methods offer a powerful tool to understand virus transmission characteristics, and can be employed in various indoor environments.
Close Contact Behaviors of University and School Students in 10 Typical Indoor
Environments.
Nan Zhang, Li Liu, Zhiyang Dou, Xiyue Liu, Xueze Yang, Doudou Miao, Yong Guo, Silan Gu, Yuguo Li, Hua Qian, Jianjian Wei.
Journal of Hazardous Materials (JHM) 2023.
Nan Zhang, Li Liu, Zhiyang Dou, Xiyue Liu, Xueze Yang, Doudou Miao, Yong Guo, Silan Gu, Yuguo Li, Hua Qian, Jianjian Wei.
Journal of Hazardous Materials (JHM) 2023.
- paper
-
abstract
Close contact, including both short-range airborne and large droplet, is recognized as the main route of SARS-CoV-2 transmission in indoor environments, however exposure risk via this route is difficult to quantify due to a lack of data showing close contact behaviors of people in typical indoor environments. A digital wearable device was developed to capture human close contact behaviors automatically based on semi-supervised learning. We collected a total of 337,056 seconds of indoor close contacts from 194 and a half hours of depth video recordings in 10 typical indoor environments. The relationship between SARS-CoV-2 exposure and close contact behaviors were evaluated based on dispersion characteristics of virus-laden droplets. People in restaurant had the highest close contact ratio (63.8%) and probability of face-to-face pattern (77.6%) during close contacts, while people in shopping center had the highest speak fraction (46.6%). University students had higher exposure potential in dormitories than school students in homes, but less exposure potential in classrooms and graduate student offices than school students in classrooms. Aerosol exposure in volume for both short-range inhalation and direct deposition on facial mucosa were highest in restaurants. Classroom is the main indoor environment for SARS-CoV-2 transmission for school students. The obtained results based on real human close contact behaviors can be used for infection risk assessment and to deploy effective interventions against close contact transmission of COVID-19 and other respiratory infections.
Close Contact Behavior-based COVID-19 Transmission and Interventions in a Subway
System
Xiyue Liu*, Zhiyang Dou*, Lei Wang, Boni Su, Tianyi Jin, Yong Guo, Jianjian Wei, Nan Zhang.
Journal of Hazardous Materials (JHM) 2022.
Xiyue Liu*, Zhiyang Dou*, Lei Wang, Boni Su, Tianyi Jin, Yong Guo, Jianjian Wei, Nan Zhang.
Journal of Hazardous Materials (JHM) 2022.
- project page
- paper
-
abstract
During COVID-19 pandemic, analysis on virus exposure and intervention efficiency in public transports based on real passenger’s close contact behaviors is critical to curb infectious disease transmission. A monitoring device was developed to gather a total of 145,821 close contact data in subways based on semi-supervision learning. A virus transmission model considering both short- and long-range inhalation and deposition was established to calculate the virus exposure. During rush-hour, short-range inhalation exposure is 3.2 times higher than deposition exposure and 7.5 times higher than long-range inhalation exposure of all passengers in the subway. The close contact rate was 56.1 % and the average interpersonal distance was 0.8 m. Face-to-back was the main pattern during close contact. Comparing with random distribution, if all passengers stand facing in the same direction, personal virus exposure through inhalation (deposition) can be reduced by 74.1 % (98.5 %). If the talk rate was decreased from 20 % to 5 %, the inhalation (deposition) exposure can be reduced by 69.3 % (73.8 %). In addition, we found that virus exposure could be reduced by 82.0 % if all passengers wear surgical masks. This study provides scientific support for COVID-19 prevention and control in subways based on real human close contact behaviors.

Top-Down Shape Abstraction Based on Greedy Pole Selection
Zhiyang Dou, Shiqing Xin, Rui Xu, Jian Xu, Yuanfeng Zhou, Shuangmin Chen, Wenping Wang, Xiuyang Zhao, Changhe Tu.
IEEE Transactions on Visualization and Computer Graphics 2020.
Zhiyang Dou, Shiqing Xin, Rui Xu, Jian Xu, Yuanfeng Zhou, Shuangmin Chen, Wenping Wang, Xiuyang Zhao, Changhe Tu.
IEEE Transactions on Visualization and Computer Graphics 2020.
- paper
-
abstract
Motivated by the fact that the medial axis transform is able to encode nearly the complete shape, we propose to use as few medial balls as possible to approximate the original enclosed volume by the boundary surface. We progressively select new medial balls, in a top-down style, to enlarge the region spanned by the existing medial balls. The key spirit of the selection strategy is to encourage large medial balls while imposing given geometric constraints. We further propose a speedup technique based on a provable observation that the intersection of medial balls implies the adjacency of power cells (in the sense of the power crust). We further elaborate the selection rules in combination with two closely related applications. One application is to develop an easy-to-use ball-stick modeling system that helps non-professional users to quickly build a shape with only balls and wires, but any penetration between two medial balls must be suppressed. The other application is to generate porous structures with convex, compact (with a high isoperimetric quotient) and shape-aware pores where two adjacent spherical pores may have penetration as long as the mechanical rigidity can be well preserved.