

EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Human Motion Generation
4Texas A&M University 5University of Pennsylvania



Abstract
We introduce Efficient Motion Diffusion Model (EMDM) for fast and high-quality human motion generation. Current state-of-the-art generative diffusion models have produced impressive results but struggle to achieve fast generation without sacrificing quality. On the one hand, previous works, like motion latent diffusion, conduct diffusion within a latent space for efficiency, but learning such a latent space can be a non-trivial effort. On the other hand, accelerating generation by naively increasing the sampling step size, e.g., DDIM, often leads to quality degradation as it fails to approximate the complex denoising distribution. To address these issues, we propose EMDM, which captures the complex distribution during multiple sampling steps in the diffusion model, allowing for much fewer sampling steps and significant acceleration in generation. This is achieved by a conditional denoising diffusion GAN to capture multimodal data distributions among arbitrary (and potentially larger) step sizes conditioned on control signals, enabling fewer-step motion sampling with high fidelity and diversity. To minimize undesired motion artifacts, geometric losses are imposed during network learning. As a result, EMDM achieves real-time motion generation and significantly improves the efficiency of motion diffusion models compared to existing methods while achieving high-quality motion generation. Our code will be publicly available upon publication.
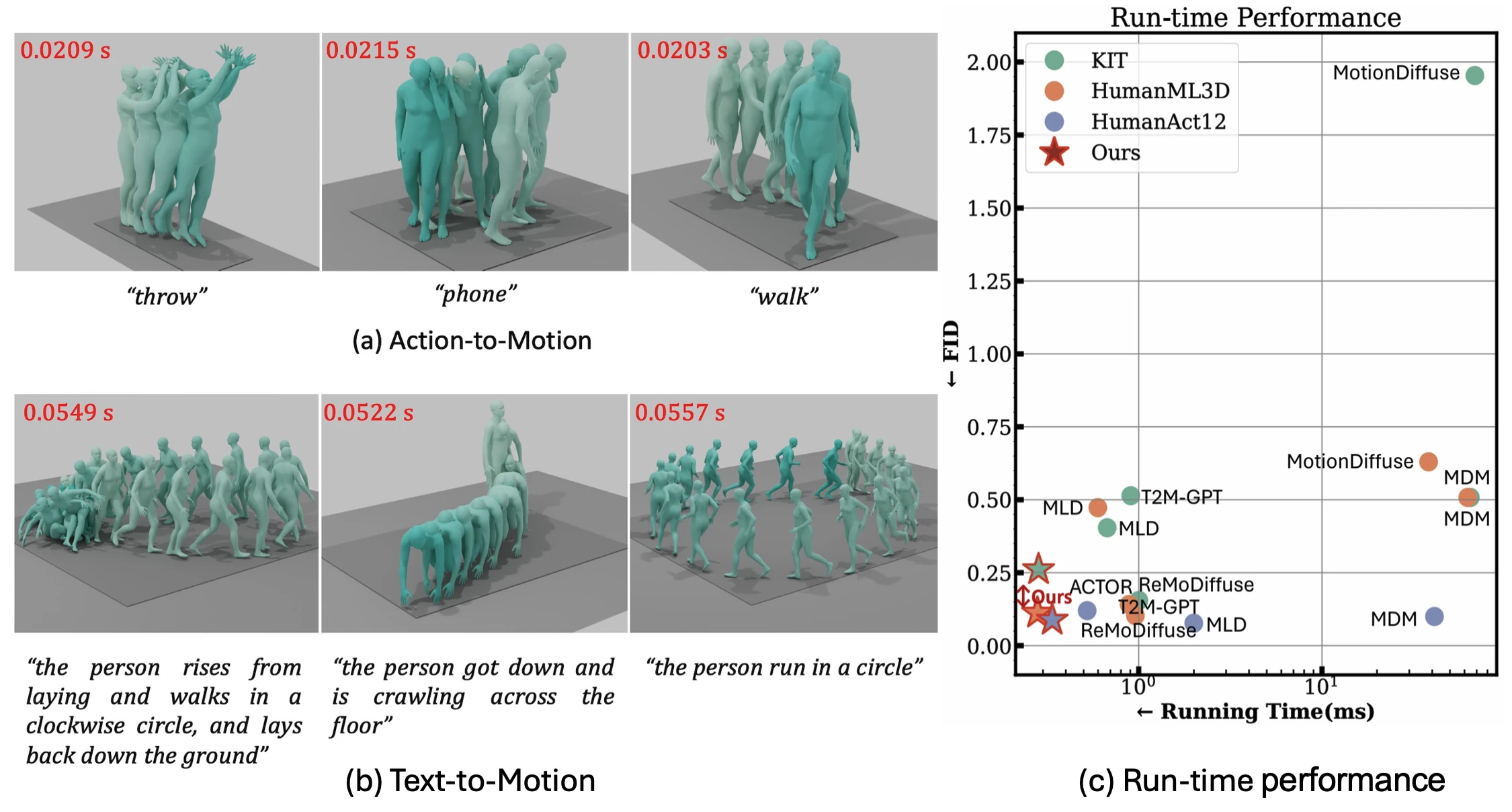
EMDM produces high-quality human motion aligned with input conditions in a short runtime. The average run time of EMDM in (a) action-to-motion and (b) text-to-motion tasks is 0.02s and 0.05s per sequence, respectively. For reference, the corresponding times for MDM are 2.5s and 12.3s. We deepen the color of the character with respect to the time step of the sequence. (c) Overall comparison of the inference time costs on the HumanML3D, KIT, and HumanAct12 datasets. For ease of illustration, the Running Time is plotted with a log scale. We compare the running time per frame vs. the FID of SOTA methods.
Framework
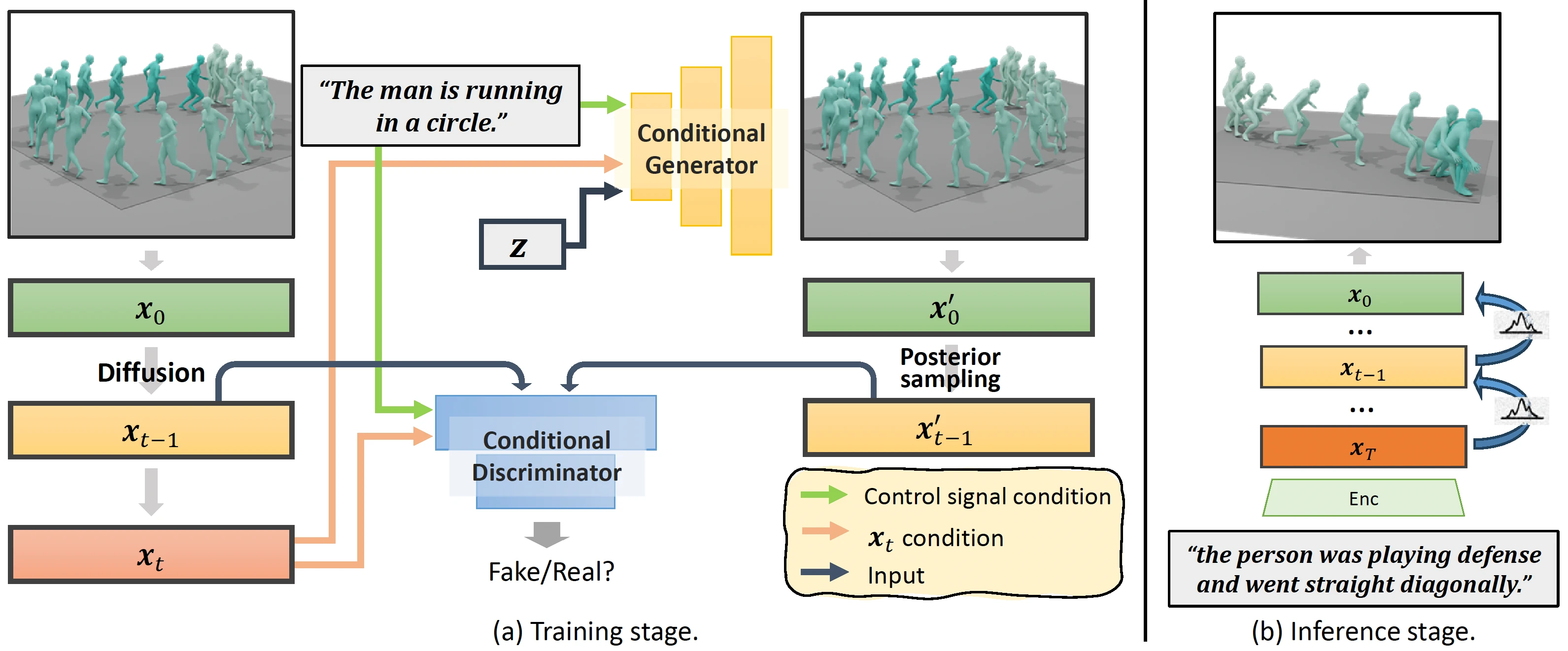
The overview of EMDM. During the training stage, we develop condition denoising diffusion GAN to capture the complex distribution of human body motion, allowing for a larger sampling step size. At the inference stage, we use the larger sampling step size for fast sampling of high-quality human motion according to the input condition.
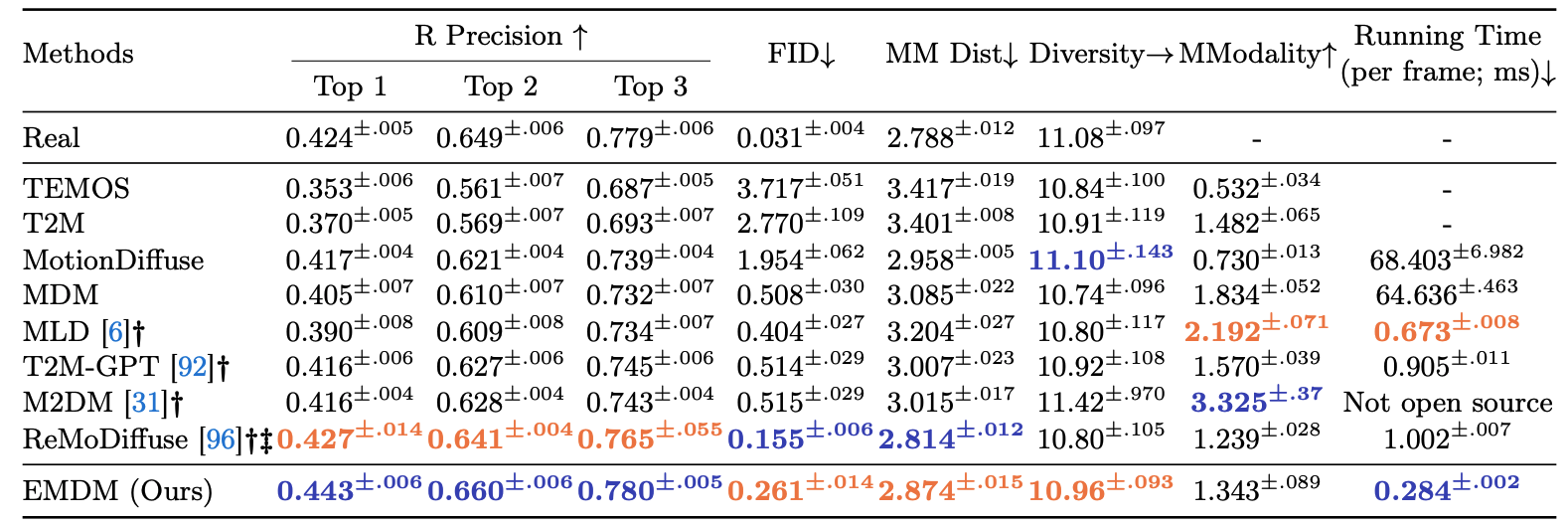
Comparisons on text-to-motion
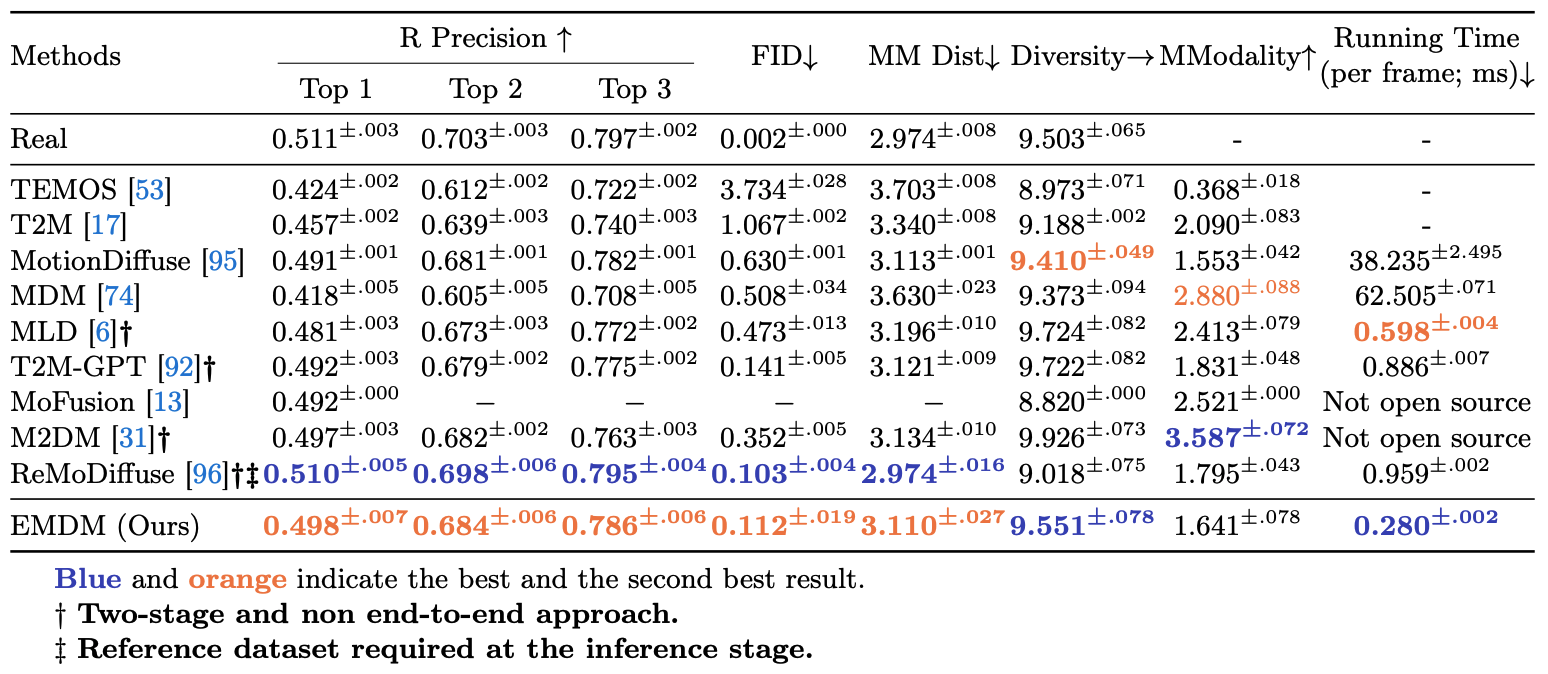
Comparison of text-to-motion task on HumanML3D. The right arrow → means the closer to real motion, the better.
Comparison of text-to-motion task on KIT. The right arrow → means the closer to real motion, the better.

Qualitative comparison of the state-of-the-art methods in text-to-motion task. We visualize motion results and real references from six text prompts. EMDM achieves the fastest motion generation while delivering high-quality motions that closely align with the text inputs.
Comparisons on action-to-motione
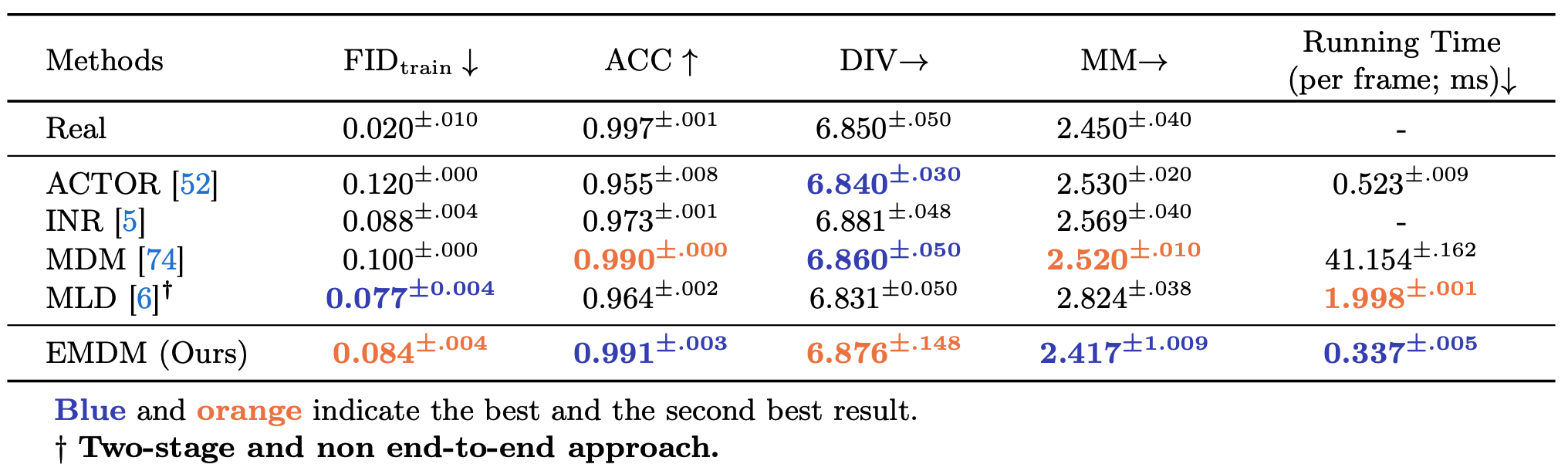
Comparison of action-to-motion task on HumanAct12: FID_train indicating the evaluated splits. Accuracy (ACC) for action recognition. Diversity (DIV) and MModality (MM) for generated motion diversity w.r.t each action label.

Qualitative comparison of the state-of-the-art methods on action-to-motion task.
More Results
Text-to-Motion

More qualitative results of EMDM on the task of text-to-motion.
Action-to-Motion

More qualitative results of EMDM on the task of action-to-motion.
Check out our paper for more details.
Citation
@article{zhou2023emdm,
title={EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Motion Generation},
author={Zhou, Wenyang and Dou, Zhiyang and Cao, Zeyu and Liao, Zhouyingcheng and Wang, Jingbo and Wang, Wenjia and Liu, Yuan and Komura, Taku and Wang, Wenping and Liu, Lingjie},
journal={arXiv preprint arXiv:2312.02256},
year={2023}
}