🎧MOSPA: Spatial Audio-Driven Human
Motion Generation
3The Hong Kong University of Science and Technology 4Macau University of Science and Technology
5ShanghaiTech University 6Texas A&M University


Abstract
Enabling virtual humans to dynamically and realistically respond to diverse auditory stimuli remains a key challenge in character animation, demanding the integration of perceptual modeling and motion synthesis. Despite its significance, this task remains largely unexplored. Most previous works have primarily focused on mapping modalities like speech, audio, and music to generate human motion. As of yet, these models typically overlook the impact of spatial features encoded in spatial audio signals on human motion. To bridge this gap and enable high-quality modeling of human movements in response to spatial audio, we introduce the first comprehensive Spatial Audio-Driven Human Motion (SAM) dataset, which contains diverse and high-quality spatial audio and motion data. For benchmarking, we develop a simple yet effective diffusion-based generative framework for human MOtion generation driven by SPatial Audio, termed MOSPA, which faithfully captures the relationship between body motion and spatial audio through an effective fusion mechanism. Once trained, MOSPA could generate diverse realistic human motions conditioned on varying spatial audio inputs. We perform a thorough investigation of the proposed dataset and conduct extensive experiments for benchmarking, where our method achieves state-of-the-art performance on this task. Our model and dataset will be open-sourced upon acceptance. Please refer to our supplementary video for more details.
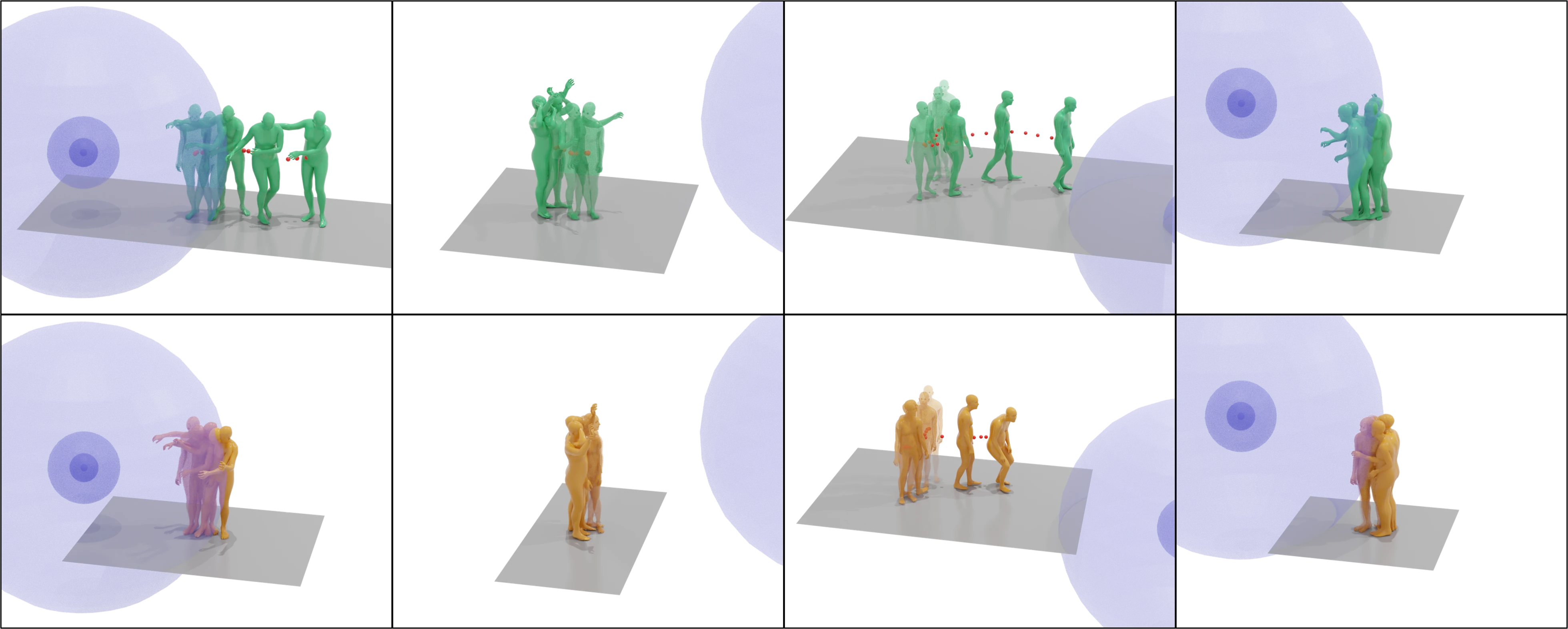
We introduce a novel human motion generation task centered on spatial audio-driven human motion synthesis. Top row: We curate a comprehensive dataset, SAM, including diverse spatial audio signals and high-quality 3D human motion pairs. Bottom row: We develop MOSPA, a simple yet effective generative model designed to produce high-quality, responsive motion driven by spatial audio. We note that the motion generation results are both realistic and responsive, effectively capturing both the spatial and semantic features of spatial audio inputs.
SAM Dataset
Statistics of the SAM dataset. The SAM dataset encompasses 27 common daily spatial audio scenarios, over 20 reaction types excluding the motion genres, and 49 reaction types. The number of subjects covered in SAM is 12, where 5 of them are female and the remaining 7 are male. It is also the first dataset to incorporate spatial audio information, annotated with Sound Source Location (SSL). The total duration of the dataset exceeds 30K seconds.
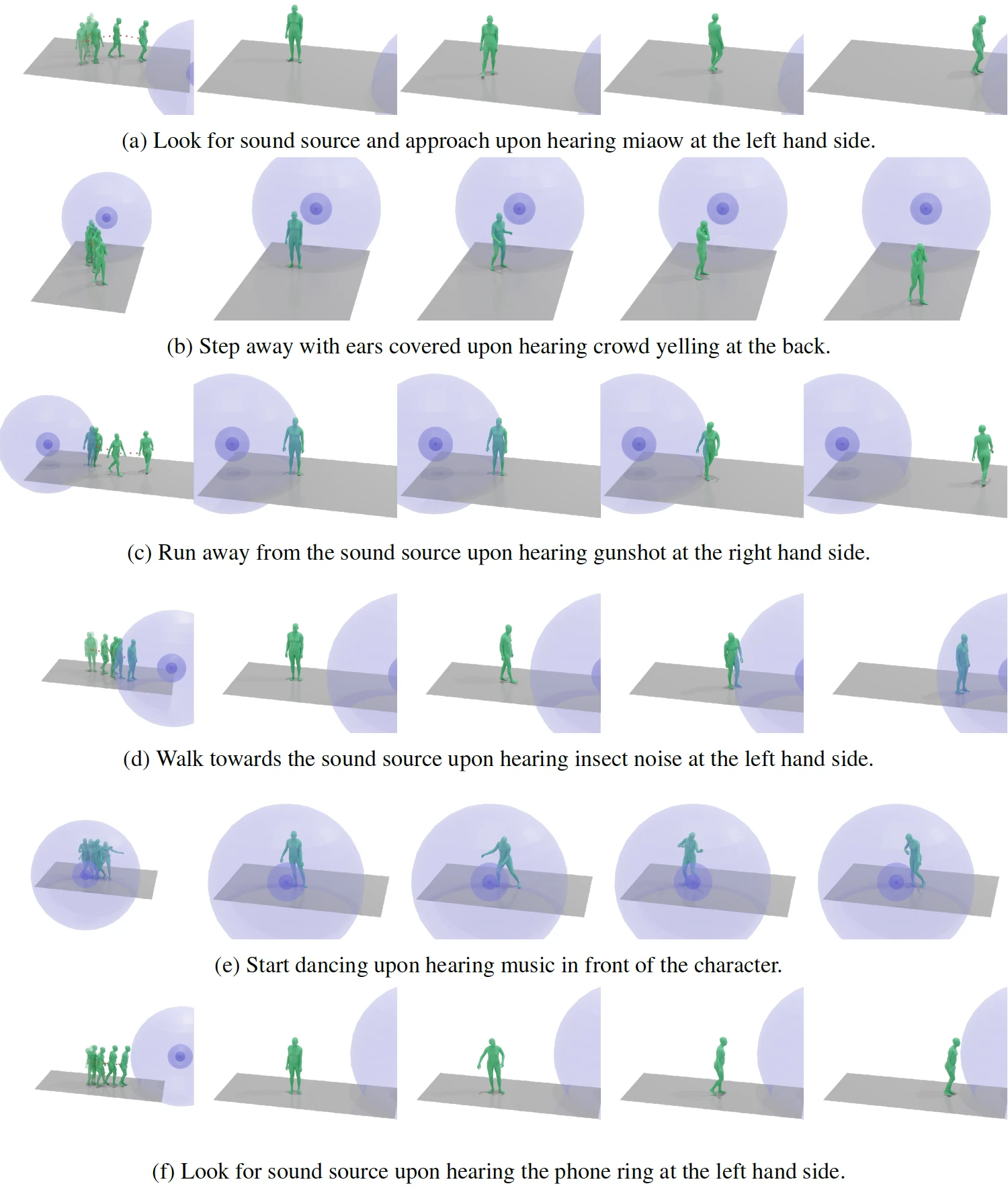
Visualization of samples from SAM with expected motions annotated. Red dots indicate the actor’s trajectory, while the blue sphere represents the sound source. The SAM dataset ensures high diversity by encompassing a broad spectrum of audio types and varying sound source locations.
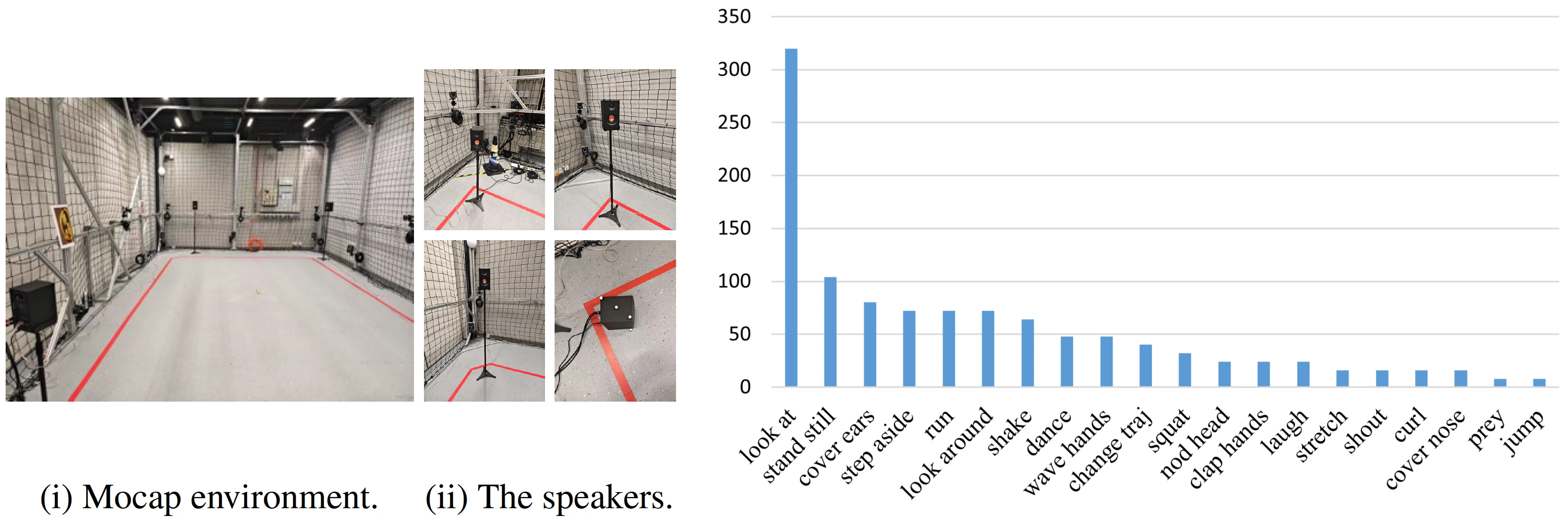
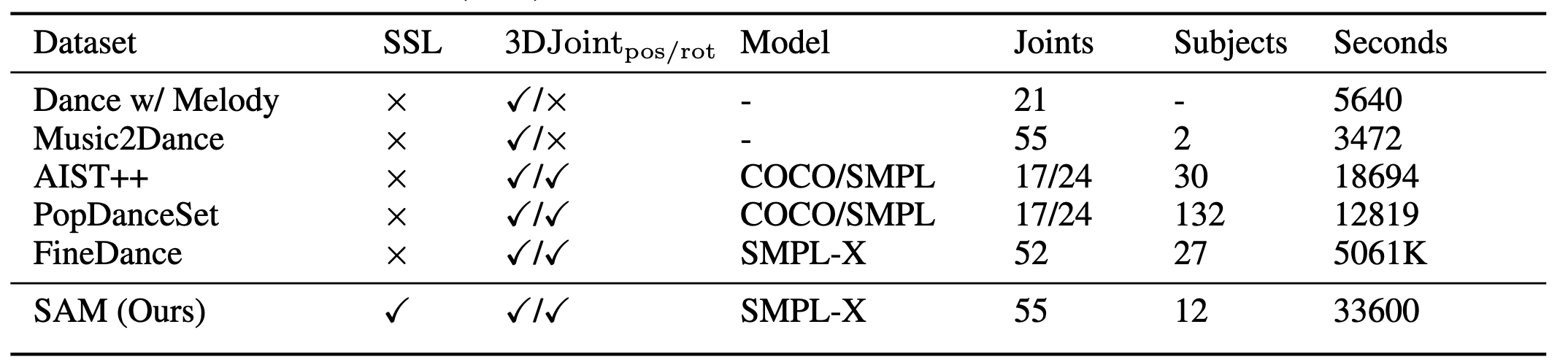
Spatial audio-driven human motion data collection setup. Statistics of action duration in the dataset.
Framework
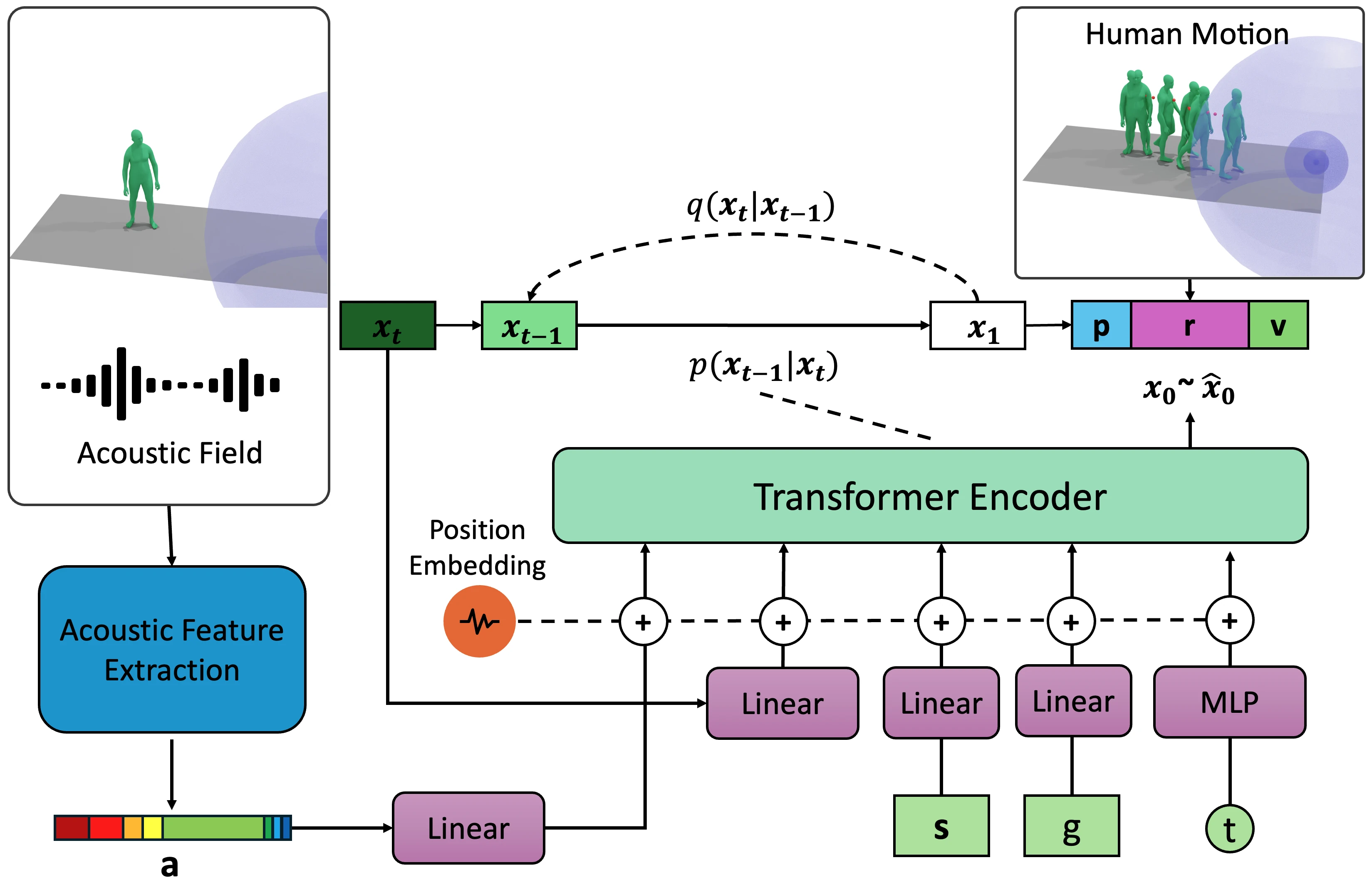
The framework of MOPSA. We perform diffusion-based motion generation given spatial audio inputs. Specifically, Gaussian noise is added to the clean motion sample $\mathbf{x_0}$, generating a noisy motion vector $\mathbf{x_t}$, modeled as $q(\mathbf{x_t}|\mathbf{x_{t-1}})$. An encoder transformer then predicts the clean motion from the noisy motion $\mathbf{x_t}$, guided by extracted audio features $\mathbf{a}$, sound source location $\mathbf{s}$, motion genre $g$, and timestep $t$.
Benchmarking
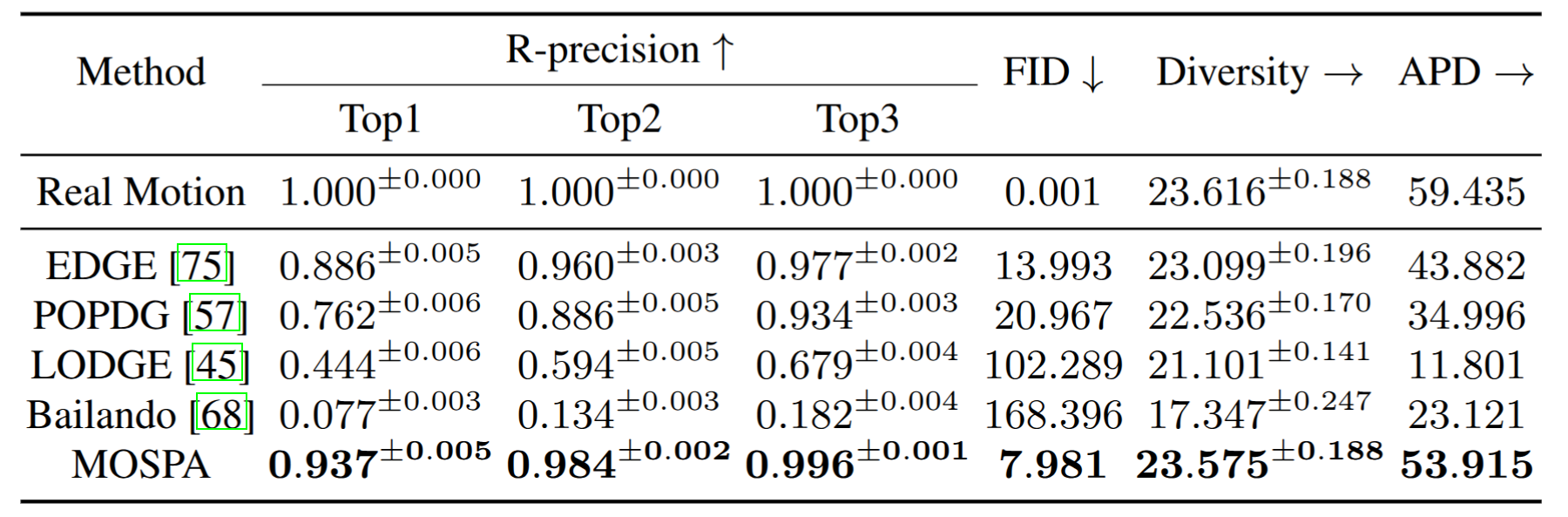
Quantitative evaluation on the SAM. MOSPA shows higher alignment with ground truth motion while preserving motion diversity. Error bars indicate 95% confidence intervals under normal distribution. → denotes closer to real motion is better.
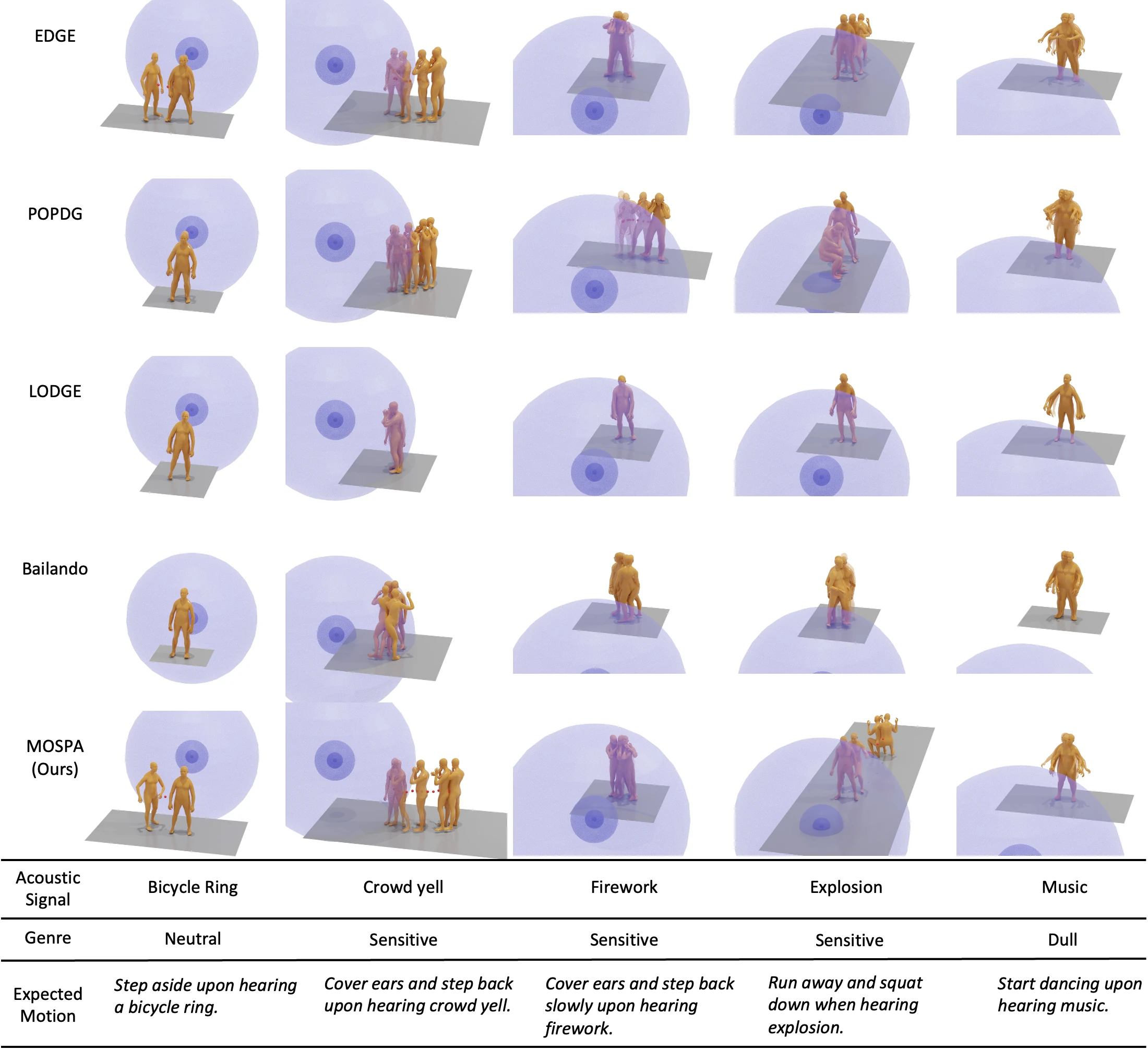
Qualitative comparison of state-of-the-art methods for the spatial audio-to-motion task. We visualize motion results from five cases. MOSPA produces high-quality movements that closely correspond to the input spatial audio. We provide Expected Motion as a description for reference.
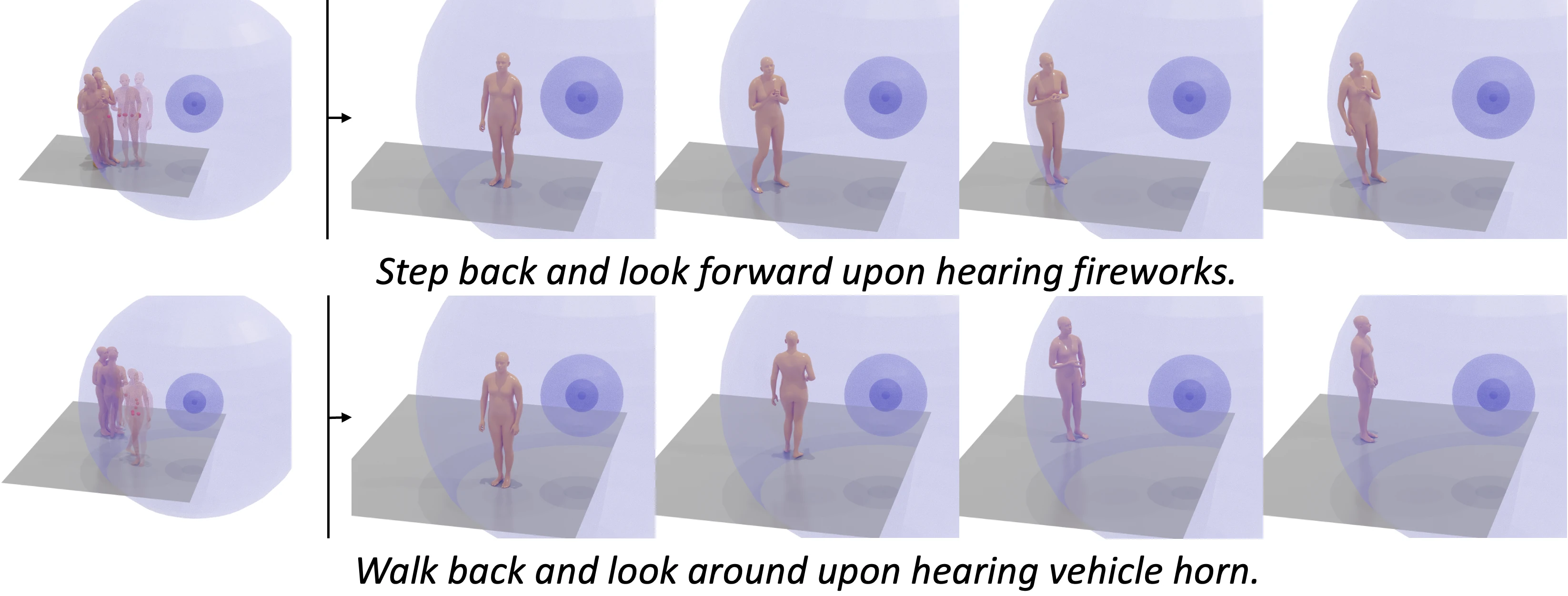
Test of MOSPA on out-of-distribution spatial audios. Descriptions of motions are provided for reference.
Spatial Audio Driven Simulated Agent Control
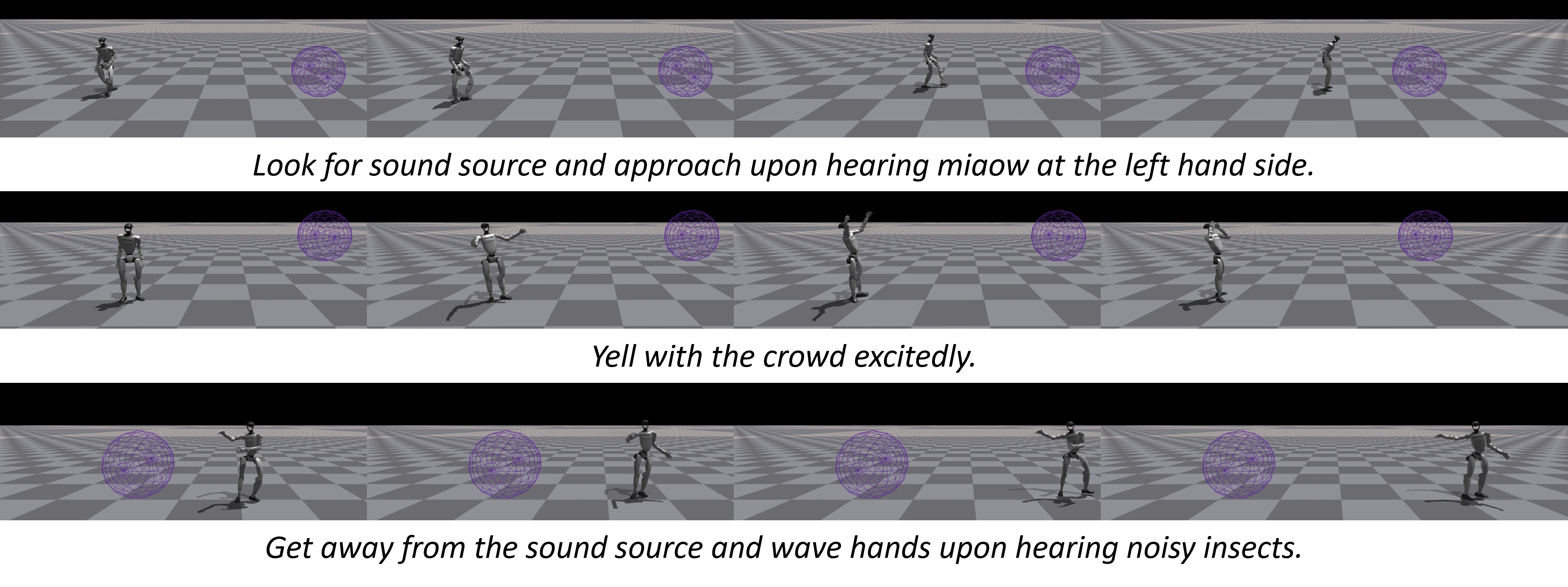
Spatial audio-driven physically simulated humanoid robot control. Descriptions of expected motion are provided for reference.
User Study
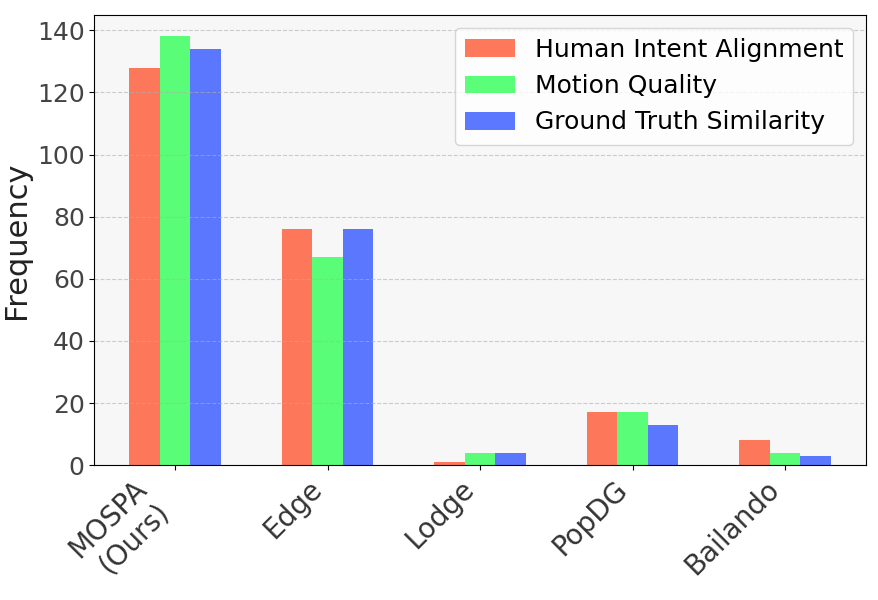
User study results. MOSPA outperforms other methods in intent alignment, motion quality, and similarity to ground truth. The bar chart shows the vote distribution across methods.
Check out our paper for more details.
Citation
@misc{xu2025mospahumanmotiongeneration,
title={MOSPA: Human Motion Generation Driven by Spatial Audio},
author={Shuyang Xu and Zhiyang Dou and Mingyi Shi and Liang Pan and Leo Ho and Jingbo Wang and Yuan Liu and Cheng Lin and Yuexin Ma and Wenping Wang and Taku Komura},
year={2025},
eprint={2507.11949},
archivePrefix={arXiv},
primaryClass={cs.GR},
url={https://arxiv.org/abs/2507.11949},
}