


TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer
5City University of Hong Kong 6Texas A&M University


Abstract
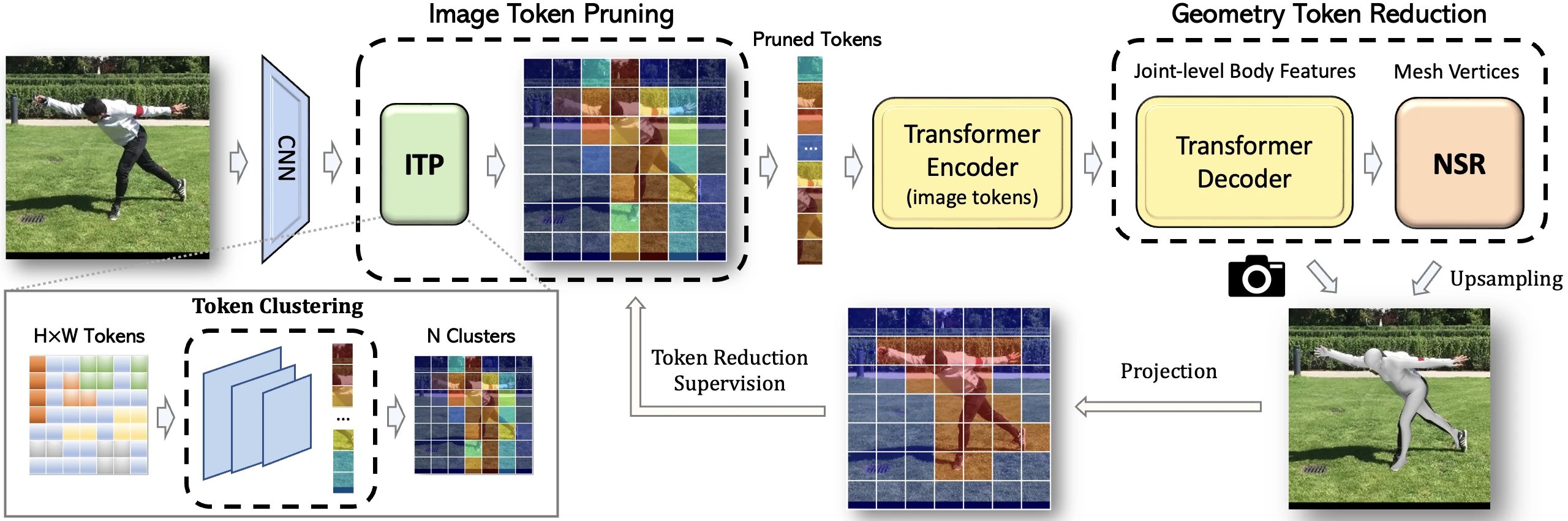
Overview of the proposed framework. Our goal is to reduce tokens for Transformer Encoder and Decoder which are critical modules in the whole pipeline. Image Token Pruner (ITP) and Neural Shape Regressor (NSR) are two lightweight components.
In this paper, we introduce a set of simple yet effective TOken REduction (TORE) strategies for Transformer-based Human Mesh Recovery from monocular images. Current SOTA performance is achieved by Transformer-based structures. However, they suffer from high model complexity and computation cost caused by redundant tokens. We propose token reduction strategies based on two important aspects, i.e., the 3D geometry structure and 2D image feature, where we hierarchically recover the mesh geometry with priors from body structure and conduct token clustering to pass fewer but more discriminative image feature tokens to the Transformer. Our method massively reduces the number of tokens involved in high-complexity interactions in the Transformer. This leads to a significantly reduced computational cost while still achieving competitive or even higher accuracy in shape recovery. Extensive experiments across a wide range of benchmarks validate the superior effectiveness of the proposed method. We further demonstrate the generalizability of our method on hand mesh recovery. Our code will be publicly available once the paper is published.
Introduction
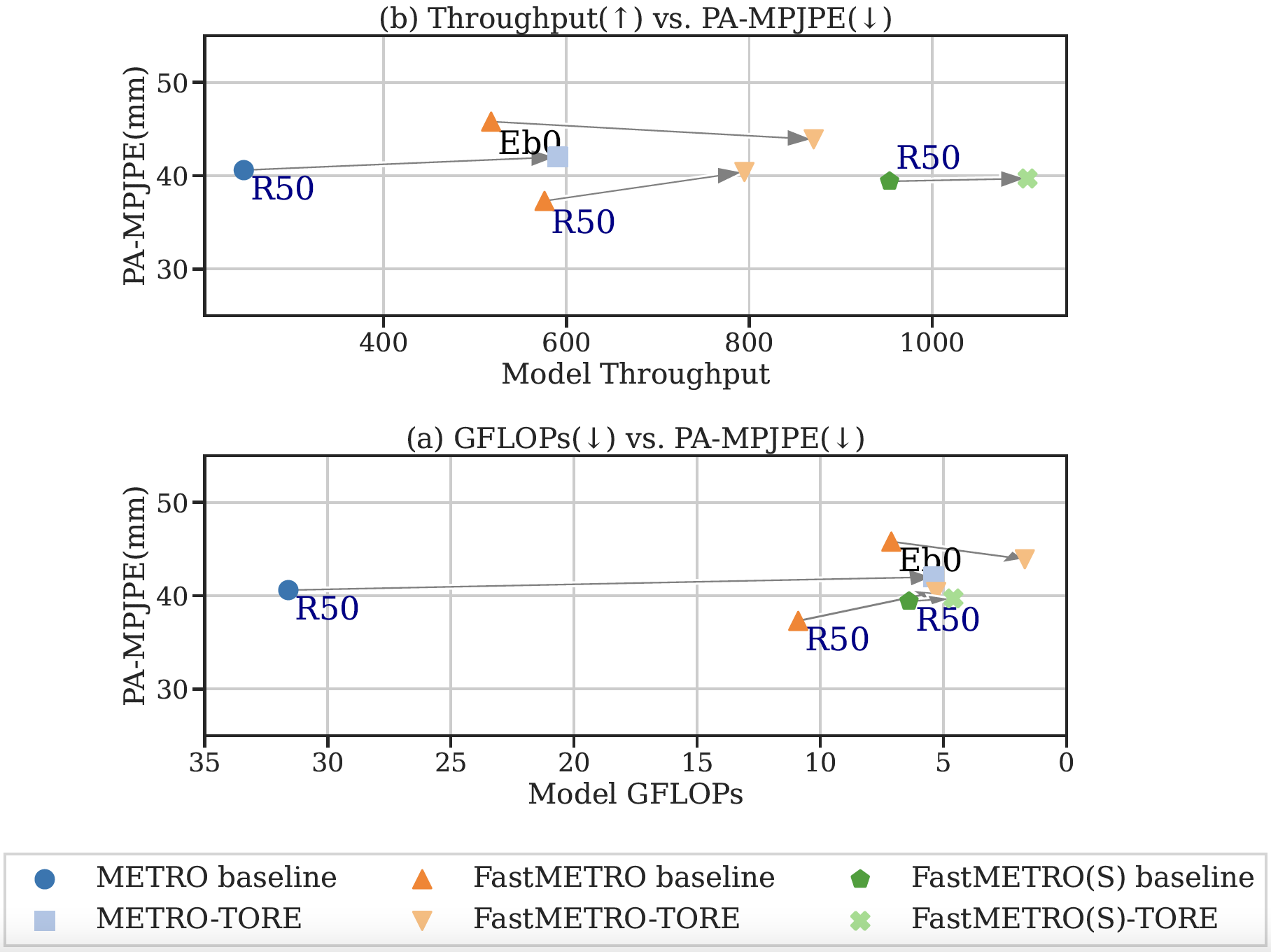
Throughput v.s. Accuracy and GFLOPs v.s. Accuracy on Human3.6M. Our method dramatically saves GFLOPs and improves throughput while maintaining highly competitive accuracy. The x-axis of the bottom GFLOPs figure is reversed for demonstration. Eb0 and R50 represent EfficientNet-b0 and ResNet-50 backbones.
We reveal the issues of token redundancy in the existing Transformer-based methods for Human Mesh Recovery (HMR). We propose effective strategies for token reduction by incorporating the insights from the 3D geometry structure and 2D image feature into the Transformer design. Our method achieves SOTA performance on various benchmarks with less computation cost. For instance, for the Transformer Encoder structure (METRO) and the Transformer Encoder-Decoder structure (FastMETRO) with ResNet-50 as backbone, our method maintains competitive accuracy while saving 82.9%, 51.4% GFLOPs and improving 139.1%, 38.0% throughput, respectively.
Effectiveness of Geometry Token Reduction (GTR)
For 3D mesh recovery, instead of querying both vertices and joints with input features simultaneously, we consider learning a small set of body tokens at the skeleton level for each body part. To recover corresponding mesh vertices, we use an efficient Neural Shape Regressor (NSR) to infer the mesh from the body features encoded by these tokens. This query process can also be interpreted as an attention matrix decomposition, by which we effectively leverage the geometric insights encoded at the skeleton level to infer the mesh structure hierarchically.

Qualitative results of GTR equipped Encoder-Decoder structure (H64) on Human3.6M and 3DPW.

Comparison with the Transformer Encoder structure METRO (M) on Human3.6M. We test with ResNet-50 (R50) and HRNet-W64 (H64) as backbones. GFLOPs^T is GFLOPs of the transformer.
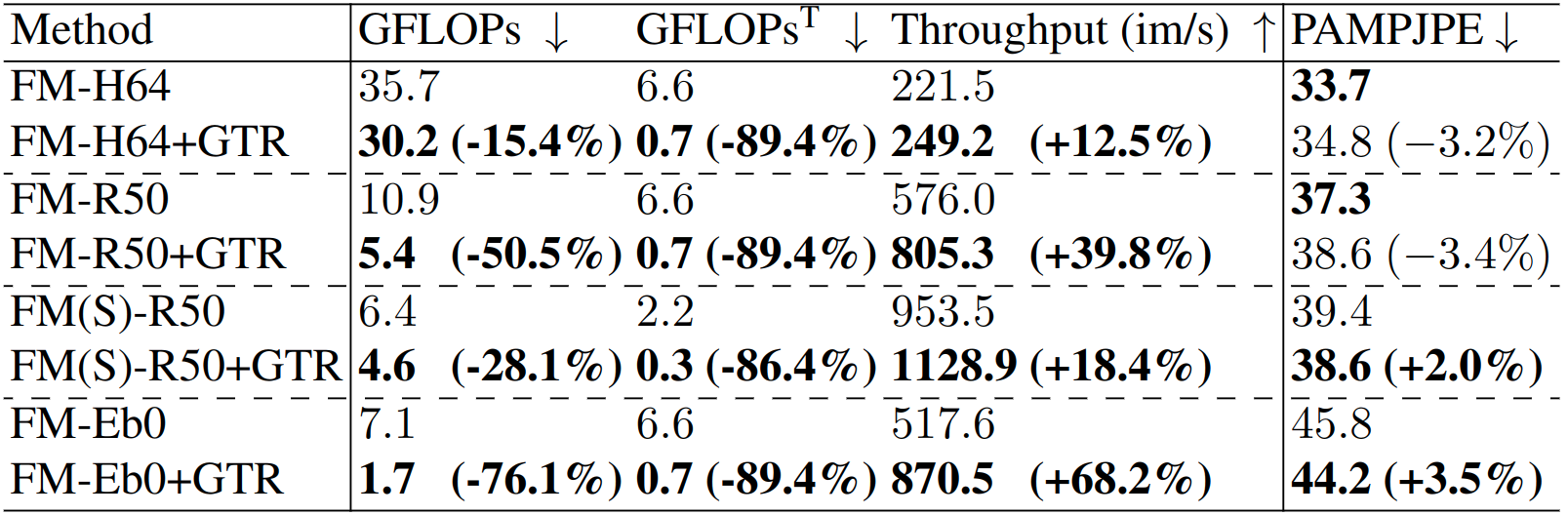
Comparison with the Transformer Encoder-Decoder structure FastMETRO (FM) on Human3.6M. We test with EfficientNet-b0 (Eb0), ResNet-50 (R50) and HRNet-W64 (H64) as backbones. GFLOPs^T stand for GFLOPs for the transformer.
Effectiveness of Image Token Pruning (ITP)
For the input image feature, we introduce a learnable token pruner to prune the tokens of patch-based features extracted by a CNN. We employ a clustering-based strategy to identify discriminative features, which results in two appealing properties: 1) the end-to-end learning of the pruner is unsupervised, avoiding the need for additional data labeling; 2) it learns semantically consistent features across various images, thus further benefiting the geometry reasoning and enhancing the capability of generalizability. These token reduction strategies substantially reduce the number of query tokens involved in the computation without sacrificing the important information.

Qualitative results of FastMETRO+GTP+ITP@$20% on Human3.6M and 3DPW.

Statistics of all proposed components (GTR + ITP) for Encoder-Decoder structure FastMETRO (FM) on Human3.6M. The backbones are EfficientNet-b0 (Eb0) and ResNet-50 (R50). GFLOPs^T stands for GFLOPs of the Transformer.
ITP helps improve the accuracy on the challenging in-the-wild 3DPW dataset, as shown below. Specifically, when further equipped with ITP, the model performance in MPVE, MPJPE and PAMPJPE are improved by 2.5mm, 1.2mm and 2.0mm, respectively. These results indicate that the ITP module learns more discriminative features and thus enhances the capability of generalization, allowing methods with ITP to achieve better performance in more challenging in-the-wild scenarios.

Influence of ITP for monocular 3D human mesh recovery on 3DPW.
Generalization on Hand Mesh Recovery

Qualitative results on FreiHAND by FastMETRO+H64+GTR+ITP@20% model.
More results
Learned semantics by ITP

Visualization of learned semantics by ITP. Note that the clustering results are consistent across different identities, i.e, different clusters correspond to different body joints.

Visualization of learned semantics by ITP. (a) projected joints. (b) projected mesh vertices. (c) mask supervision. (d) scores predicted by ITP.
Vertex-Body Feature Interactions Modeled by GTR

Visualization of cross-attention between joint and vertices. Samples are from Human3.6M and 3DPW.
Check out our paper for more details.
Citation
@InProceedings{Dou_2023_ICCV,
author = {Dou, Zhiyang and Wu, Qingxuan and Lin, Cheng and Cao, Zeyu and Wu, Qiangqiang and Wan, Weilin and Komura, Taku and Wang, Wenping},
title = {TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {15143-15155}
}