
Text2Interact: High-Fidelity and Diverse Two-Person Interaction Generation from Text


Abstract
Generating realistic and diverse human-human interactions from text remains a fundamental but challenging problem in vision, graphics, and robotics. Current approaches face two main limitations: (i) interaction synthesis requires both high-quality individual motion and precise spatiotemporal coordination, yet existing datasets are too small to support such complexity, limiting generalization; and (ii) complex interactions often demand detailed textual descriptions, but sentence-level embeddings fail to capture fine-grained semantics. We address these issues with two contributions. First, we introduce InterCompose, a scalable data synthesis framework that combines the general knowledge of large language models with strong single-person motion priors to generate high-quality two-person interactions beyond existing distributions. Second, we propose Text2Interact, which employs word-level attention for fine-grained text-motion alignment and an adaptive supervision signal that dynamically weights body parts based on interaction context to enhance realism. Extensive experiments demonstrate that our approach substantially improves motion diversity, semantic alignment, and realism over state-of-the-art baselines. Our code and models will be released for reproducibility.
.png)
(a) Our generative two-person motion composition framework, InterCompose, synthesizes plausible and diverse interactions from generated textual descriptions and a single-person motion condition (yellow). (b) Our interaction generation framework Text2Interact generates high-quality and plausible interactions faithful to text. A deeper color indicates a later time.
Method
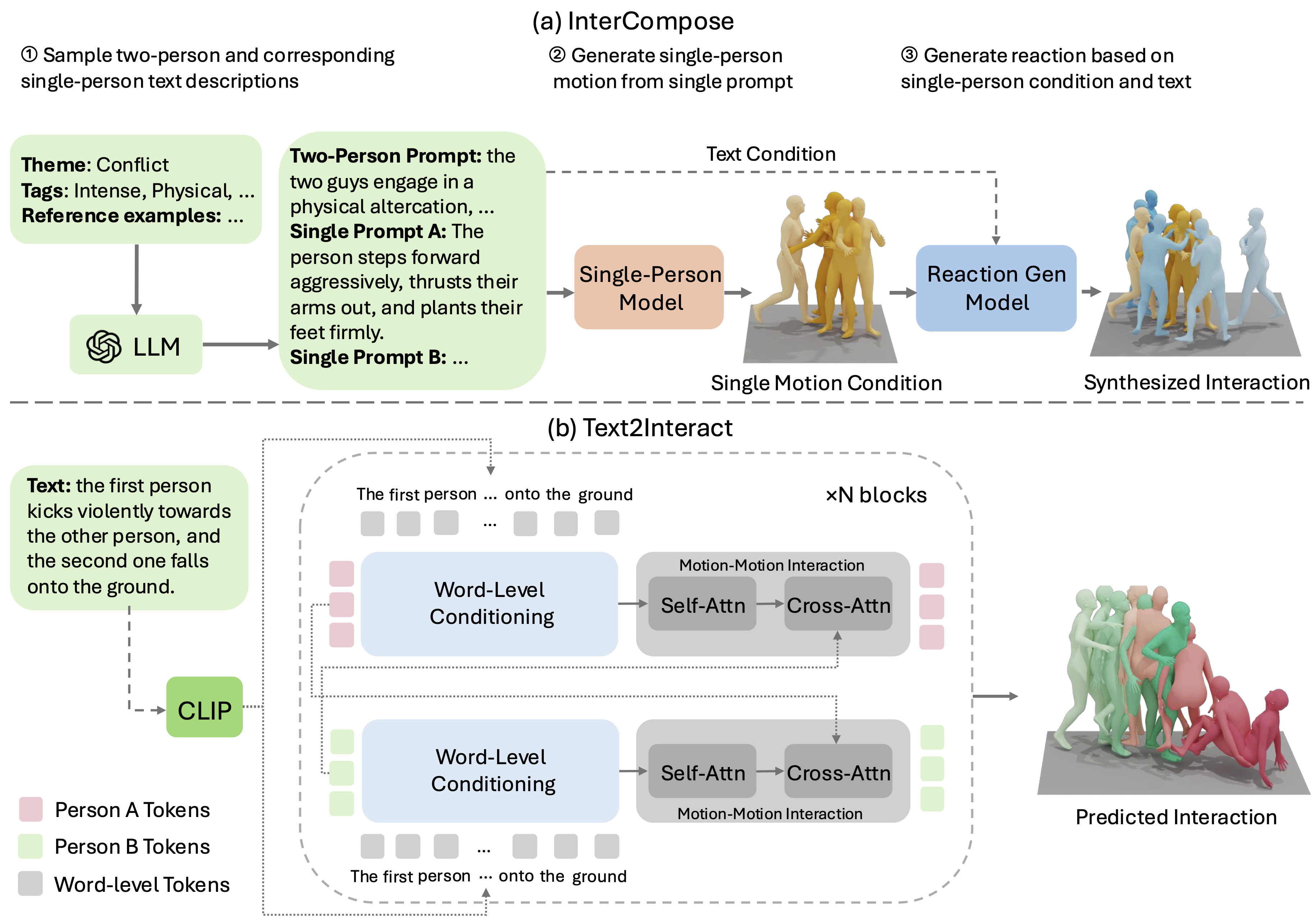
Overview of the proposed frameworks. (a) InterCompose: sample interaction and single-person descriptions via an LLM, generate a single-person motion from a motion prior (Guo et al., 2024), then compose the second agent with a reaction model conditioned on the two-person prompt and the motion prior. (b) Text2Interact: an N-block generator with word-level conditioning and motion-motion interaction. Each block cross-attends motion tokens to CLIP word tokens (Radford et al., 2021), followed by self-attention and inter-agent cross-attention to model individual motion and interactions.
Experimental Results
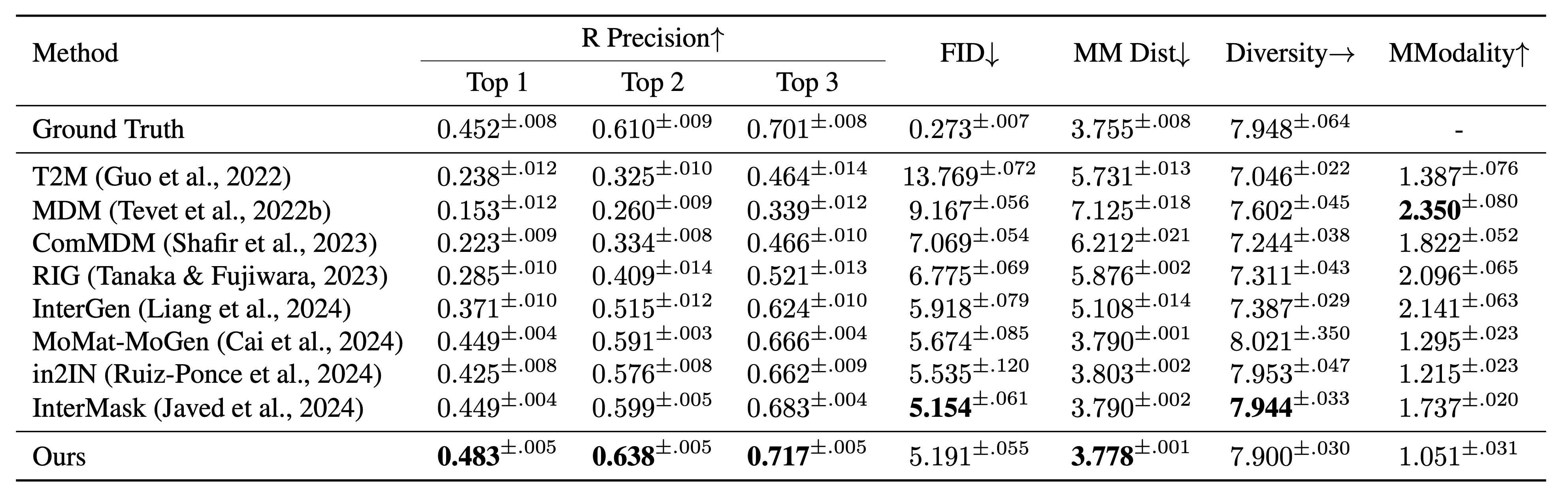
Quantitative comparison with state-of-the-art methods on the InterHuman (Liang et al., 2024) test sets. ± indicates a 95% confidence interval and → means the closer to ground truth the better. Boldface indicates the best result.

Qualitative comparisons of interaction generation results from Text2Interact and InterMask. Our method produces results with better text-motion alignment and is more robust to implausible poses. A deeper color indicates a later time.
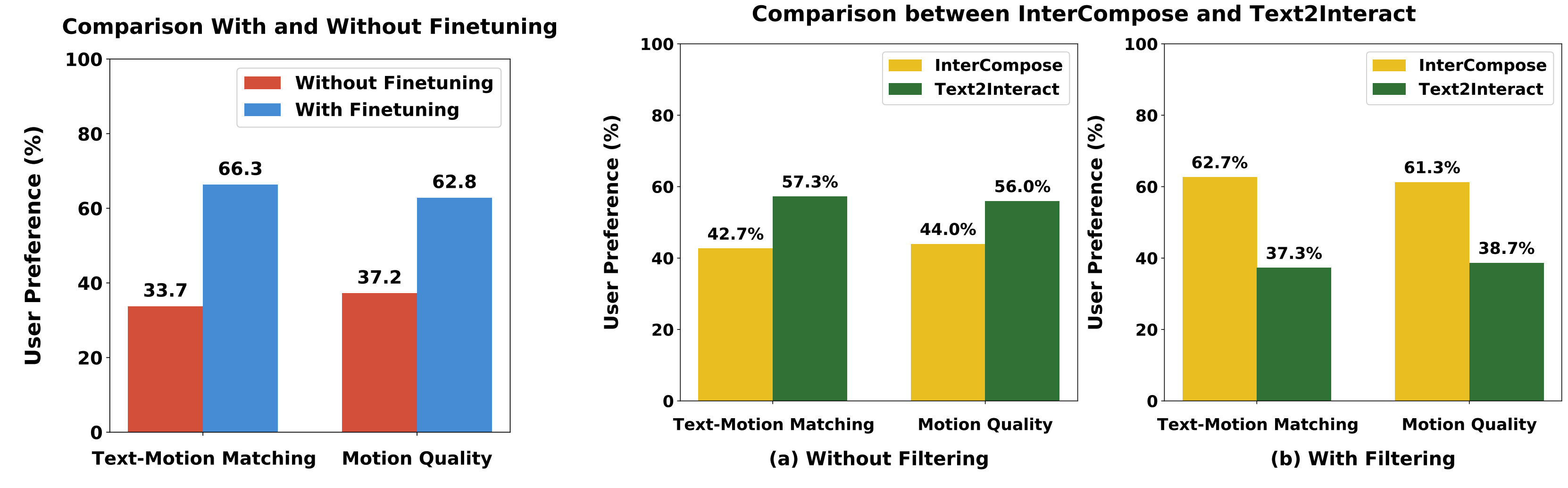
User preference study results. Left: User preference study results of Text2Interact with and without fine-tuning on synthetic data. Right: Comparison of motion generation results using InterCompose and Text2Interact, (a) without filtering, and (b) with filtering. The motion quality and text-motion matching of InterCompose surpass Text2Interact only after filtering.
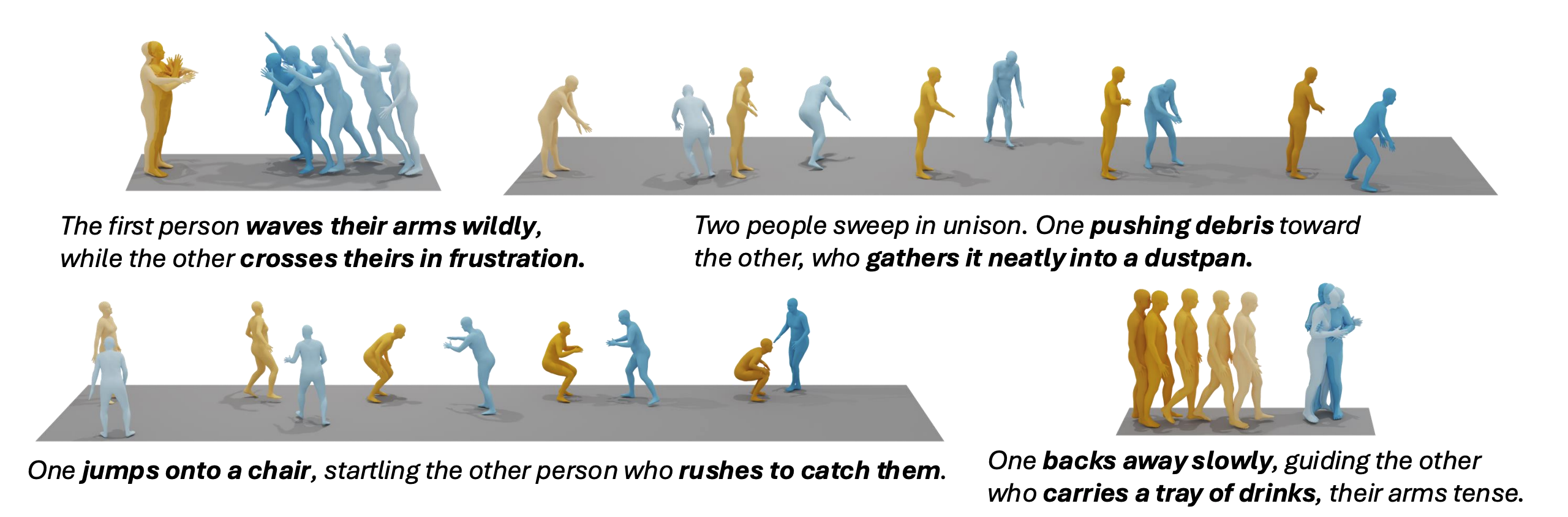
Qualitative samples of InterCompose. Prompts are synthesized by DeepSeek V3. The yellow motion is synthesized by the single-person motion generator, while the blue motion is generated by the reaction model with the yellow as the condition. A deeper color indicates a later time.
Citation
@article{wu2026text2interact,
title={Text2interact: High-fidelity and diverse text-to-two-person interaction generation},
author={Wu, Qingxuan and Dou, Zhiyang and Guo, Chuan and Huang, Yiming and Feng, Qiao and Zhou, Bing and Wang, Jian and Liu, Lingjie},
journal={ICLR 2026},
year={2026}
}
This page is Zotero translator friendly. Page last updated Feb. 2025.